Token简介
Token,直译为“令牌”或“代币”,在大语言模型(LLM)中,它是文本信息处理的基本单位。
Token的分类
通常情况下,一个token可以是一个单词、一个标点符号、一个数字,或者是其他更小的文本单元,如子词或字符。
单词级token
即token是按照单词进行划分的。一个句子中的每个单词通常都会成为一个独立的token。
例如,一句话"我是中国人"可以划分为三个单词级的token——"我"、"是"、"中国人"
标点符号级token
除了单词,标点符号通常也作为独立的token存在。这是因为标点符号在语义和语法上都具有重要的作用。
例如,一句问候"你最近好么?",最后的问号也是一个独立的token。
子词级token
为了更好地处理复杂的语言情况,有时候将单词进一步划分为子词级的token。
例如,单词"unhappiness"可以被划分为子词级token——"un-"、"happiness"
现在大模型比较流行的子词级token还有字节对编码(BPE),对一些频繁出现的字词进行合并实现。
字符级token
在某些情况下,特别是在字符级别的处理任务中,文本会被划分为字符级token。这样做可以处理字符级别的特征和模式。
例如,在句子"Great!"中,"G"、"r"、"e"、"a"、"t"分别是六个字符级token。
Token的计量
如果要判断输入输出到底有多少token,暂时没有统一的方法。我们根据经验总结了两条规律:
(1)对于英文,1个token大约是4个字符或0.75个单词。通常来说,也就是1000个Token约等于750个英文单词。
(2)对于中文,1000个Token通常等于400~500个汉字。
Token为什么重要
体现在三方面
算力成本:每次对话消耗token量就是我们的算力账单,GPT-4每千token约0.3元人民币。Token因此成为了AI世界的“数字货币”,直接关联着每一次交互的成本。
内容长度:ChatGPT-3.5最多支持4096 tokens(约3000汉字)
回答质量:超出限制会"失忆",重要信息要前置!
Token的作用
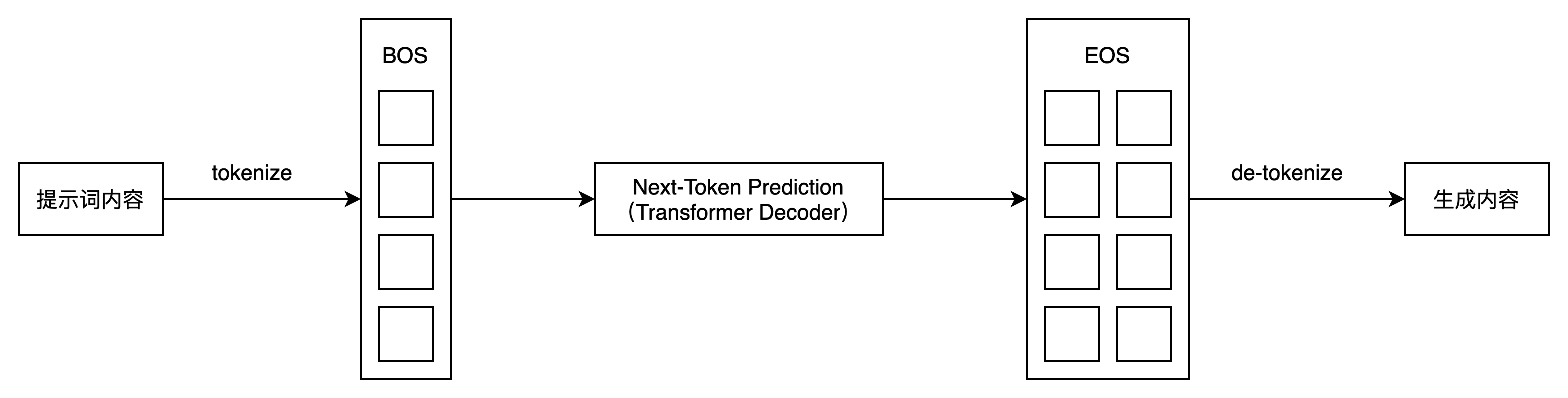
大模型处理中,将文本划分为token是对文本进行分析和处理的基本步骤之一。
以下是人工智能处理过程
Token相关发展数据
包括国内数据和国外数据
国内发展数据
2024年中国家统计局发布数据,2024年初中国AI行业每天消耗1000亿个Token。
2025年8月14日,国家统计局发布数据,截止2025年6月,中国AI行业每天消耗30万亿个Token,短短一年半时间暴涨了300倍。
2025年8月16日,华为推出的UCM推理算法,把第一个Token的响应时间整整缩短了90%,处理速度还提升了22倍,这直接让中国AI在推理效率上接近了国际一流水平。
国外发展数据
2025年第一季度,谷歌处理的AI推理Tokens总量达到约634万亿(634T),月度推力量为211万亿。微软同期处理量约为100万亿(100T)。
2025年4月,谷歌月度推理量已飙升至480万亿,较一年前的9.7万亿激增50倍。
Cursor这家公司,成了最快达到5亿美元ARR的AI企业;OpenAI的年收入也突破了100亿美元。这说明了一个正向循环:Token越多,收入越高,然后又能投入更多算力去优化模型,进一步推动增长。这就是所谓的“Token-收入-算力再投入”的飞轮效应。