Amoro优化器简述
Amoro对表的优化是通过优化器来完成的,目前支持以下优化器:flink优化器、spark优化器、standalone优化器。
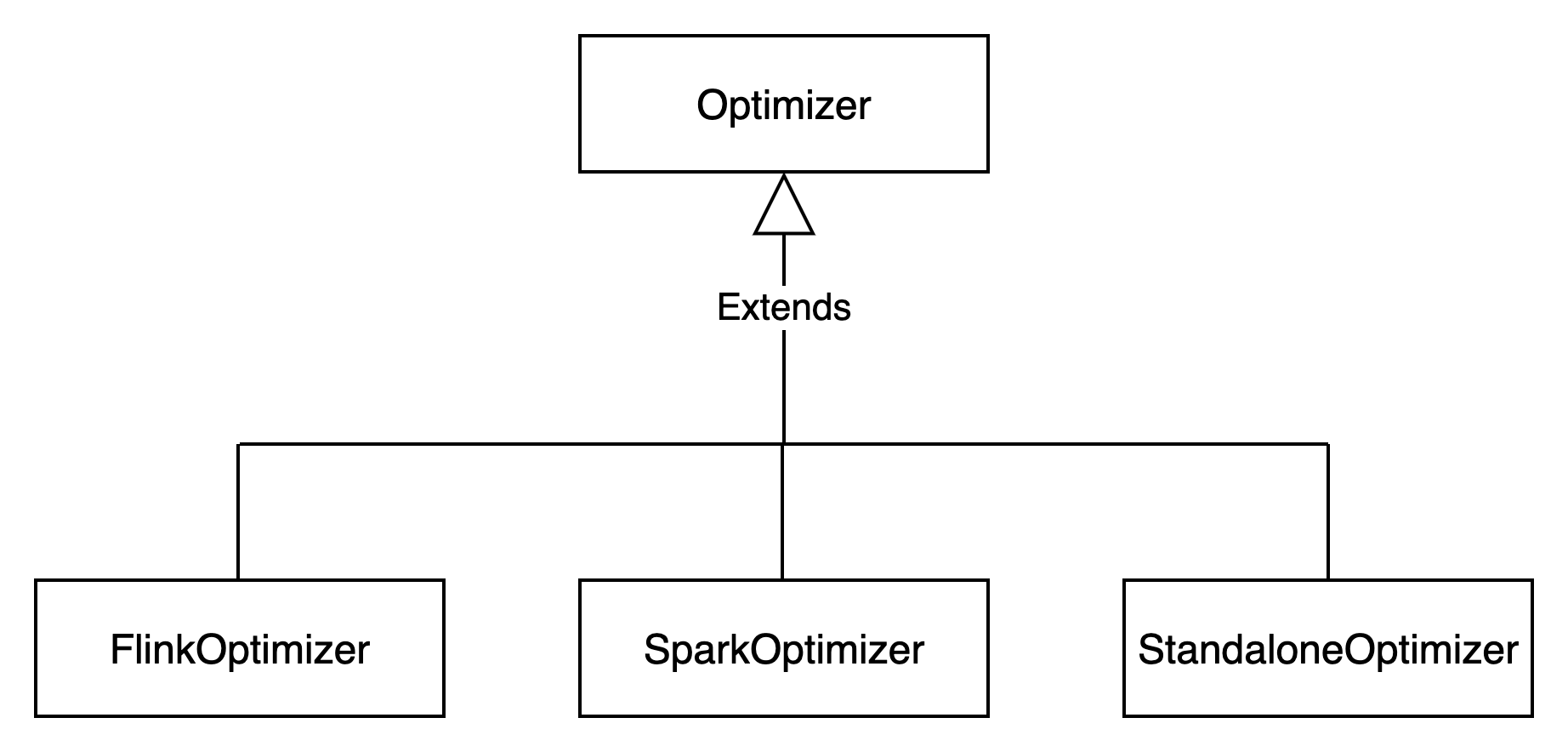
Optimizer类型
Optimizer表示不同的优化器类型。
Optimizer的类型如下图所示
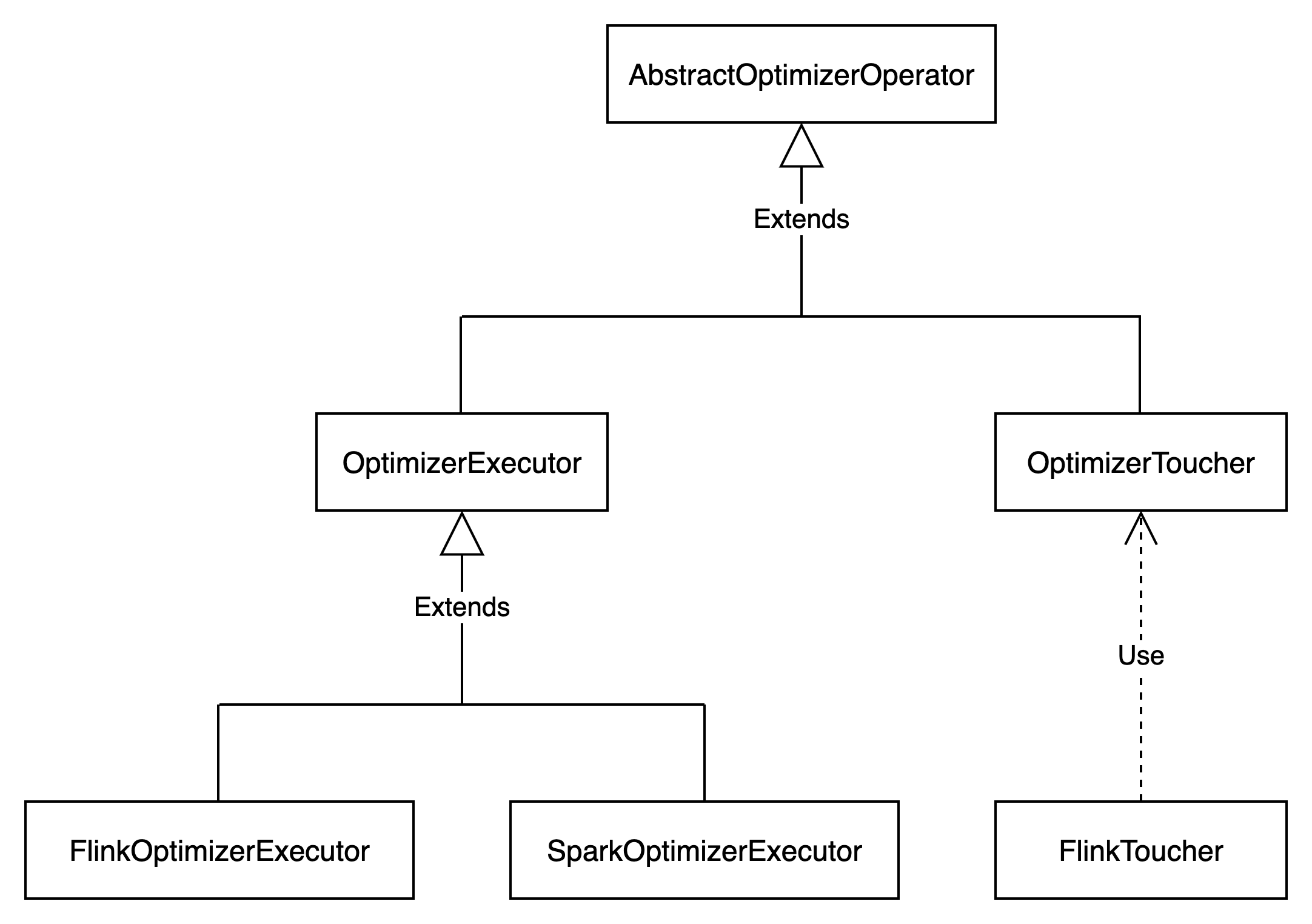
OptimizerExecutor类型
OptimizerExecutor表示优化器执行器,包含优化器的处理逻辑。
OptimizerExecutor的类型如下图所示
任务的执行在OptimizerExecutor中。
Amoro优化器类结构
Amoro优化器完整类结构如下图所示:
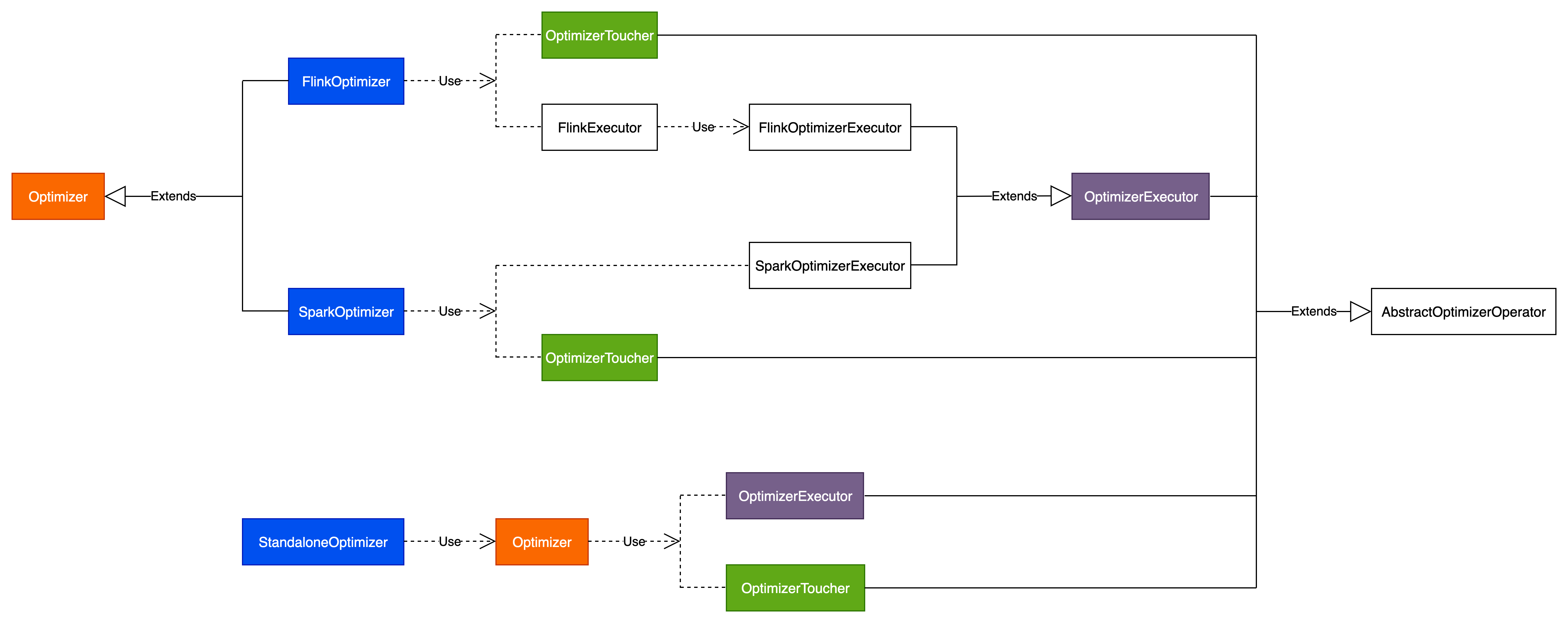
下面分别对这些优化器进行解析。
优化器配置
优化器配置表示启动优化器进程的一些命令行配置,定义在org.apache.amoro.optimizer.common.OptimizerConfig类中,包含以下配置
Flink优化器
跟踪flink优化器的执行过程。
Flink优化器执行入口
Flink优化器进程由org.apache.amoro.server.manager.FlinkOptimizerContainer启动,进程main函数在org.apache.amoro.optimizer.flink.FlinkOptimizer中定义,main函数即为Flink优化器的执行入口,逻辑如下:
org.apache.amoro.optimizer.flink.FlinkOptimizer#main
StreamExecutionEnvironment env
OptimizerConfig optimizerConfig
// 计算优化器内存分配
calcOptimizerMemory(optimizerConfig, env);
// 初始化FlinkOptimizer
Optimizer optimizer = new FlinkOptimizer(optimizerConfig);
env.addSource(new FlinkToucher())
.transform(new FlinkExecutor())
.addSink(new DiscardingSink<>())
// 启动flink任务,指定任务名称
env.execute("amoro-flink-optimizer-{resourceId}")优化器内存计算
calcOptimizerMemory方法计算flink任务所需的内存,逻辑如下。
org.apache.amoro.optimizer.flink.FlinkOptimizer#calcOptimizerMemory(config)
// 获取jobmanager.memory.process.size配置
MemorySize jobMemorySize
// 获取taskmanager.memory.process.size配置
MemorySize taskMemorySize
// jobMemorySize或taskMemorySize为空,表示本地运行,无需计算
if (jobMemorySize == null || taskMemorySize == null) return;
// 获取优化器并发度,由“-p”配置
int parallelism
// 获取taskmanager.numberOfTaskSlots配置
int numberOfTaskSlots
// 计算总内存大小,注意单位一致
int memorySize = jobMemorySize + (parallelism / numberOfTaskSlots) * taskMemorySize;
// 如果parallelism不是numberOfTaskSlots的整数倍,则还需要加一个task的内存
if (parallelism % numberOfTaskSlots != 0) memorySize += taskMemorySize;
config.setMemorySize(memorySize);初始化FlinkOptimizer
初始化FlinkOptimizer实例,并根据优化器并发度初始化FlinkOptimizerExecutor列表
new FlinkOptimizer(optimizerConfig);
// 初始化OptimizerToucher实例
OptimizerToucher toucher
// 根据优化器并发度初始化FlinkOptimizerExecutor列表,每个FlinkOptimizerExecutor表示一个线程,线程号为数字,从0开始
OptimizerExecutor[] executors = new FlinkOptimizerExecutor[config.getExecutionParallel()]
FlinkOptimizer
// 如果资源id不为空,则注册此属性
if (config.getResourceId() != null) {
toucher.withRegisterProperty("resource-id", config.getResourceId());
}Spark优化器
跟踪spark优化器的执行过程。
Spark优化器执行入口
Spark优化器为org.apache.amoro.optimizer.spark.SparkOptimizer,AMS通过org.apache.amoro.server.manager.SparkOptimizerContainer来启动对应的SparkOptimizer。
SparkOptimizer的main函数执行过程如下:
spark优化器为org.apache.amoro.optimizer.spark.SparkOptimizer,main函数为执行入口,当
org.apache.amoro.optimizer.spark.SparkOptimizer#main(args)
// 解析入参,包含并发度、资源名称、ams连接等信息
config = new OptimizerConfig(args);
// 创建SparkSession实例,名称为"amoro-spark-optimizer-{入参id的配置值}"
spark = SparkSession.builder()
// 创建应用上下文信息
jsc = new JavaSparkContext(spark.sparkContext());
// 设置内存大小,值为spark.driver.memory + spark.executor.memory * {并发度}
config.setMemorySize()
// 初始化SparkOptimizer实例
optimizer = new SparkOptimizer(config, jsc);
// 初始化OptimizerToucher构建工厂方法
() -> new OptimizerToucher(config)
// 初始化SparkOptimizerExecutor构建工厂,i表示线程号
(i) -> new SparkOptimizerExecutor(jsc, config, i))
// 调用OptimizerToucher构建工厂创建OptimizerToucher实例
toucher = toucherFactory.get();
// 调用SparkOptimizerExecutor构建工厂创建OptimizerExecutor实例,数量为配置的并发度
executors = new OptimizerExecutor[config.getExecutionParallel()];
// 注册resource-id信息
toucher.withRegisterProperty(“resource-id”, config.getResourceId());
// 获取optimizer中的toucher属性,OptimizerToucher的主要作用是维护优化器与AMS(Amoro Management Service)之间的通信和状态同步
toucher = optimizer.getToucher()
// 注册job-id信息
toucher.withRegisterProperty(“job-id”, spark.sparkContext().applicationId());
// 启动优化器
optimizer.startOptimizing();
LOG.info("Starting optimizer with configuration:{}", config);
// 为每一个executor启动一个线程,线程号为“Optimizer-executor-{optimizerExecutor.getThreadId()}”
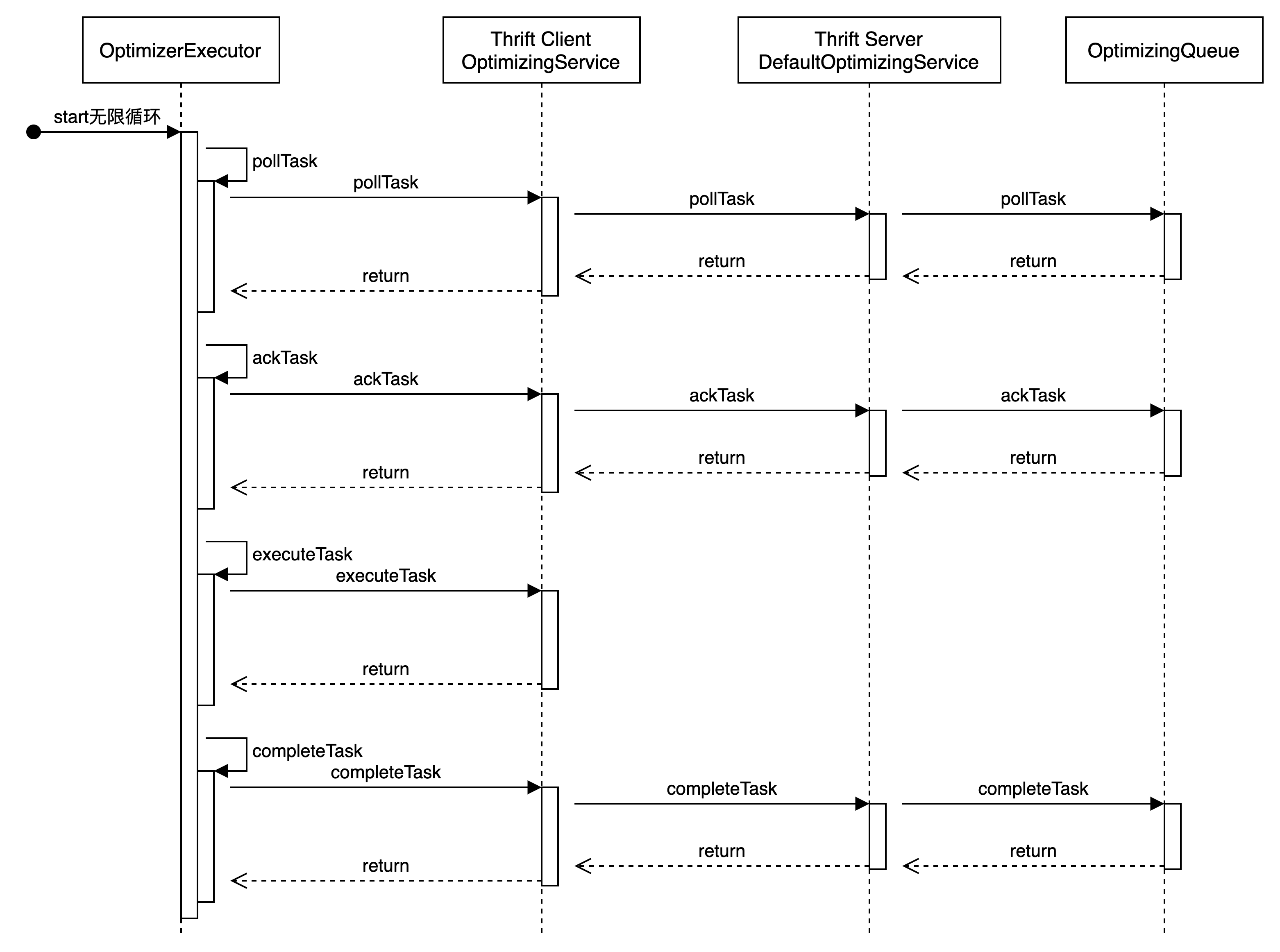
executors.forEach(optimizerExecutor -> new Thread(optimizerExecutor::start).start());OptimizerExecutor启动任务
OptimizerExecutor#start过程如下图所示:
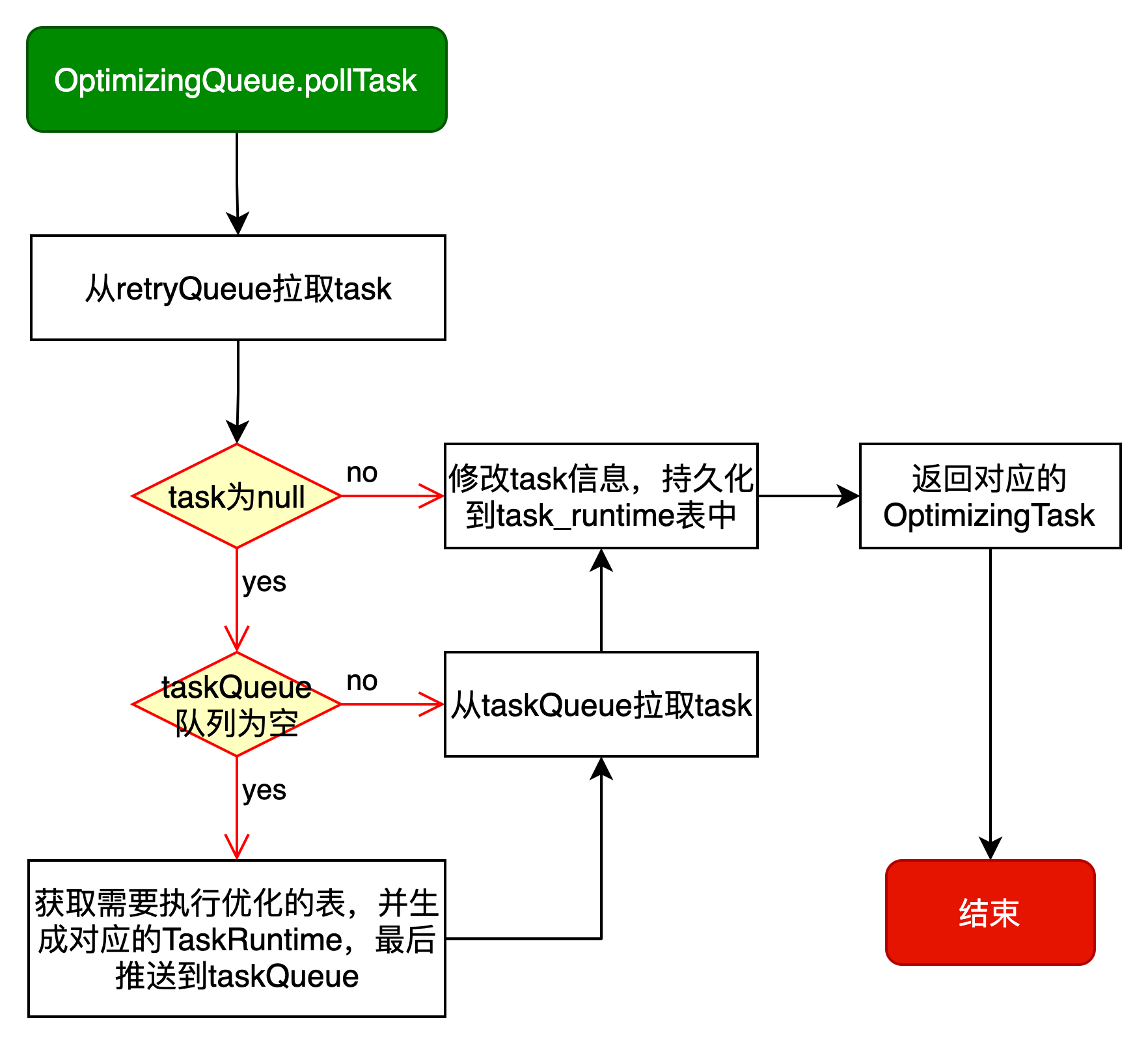
拉取任务信息
OptimizerExecutor#pollTask的逻辑如下图所示:
task_runtime记录着任务执行记录,对应状态机如下图所示:
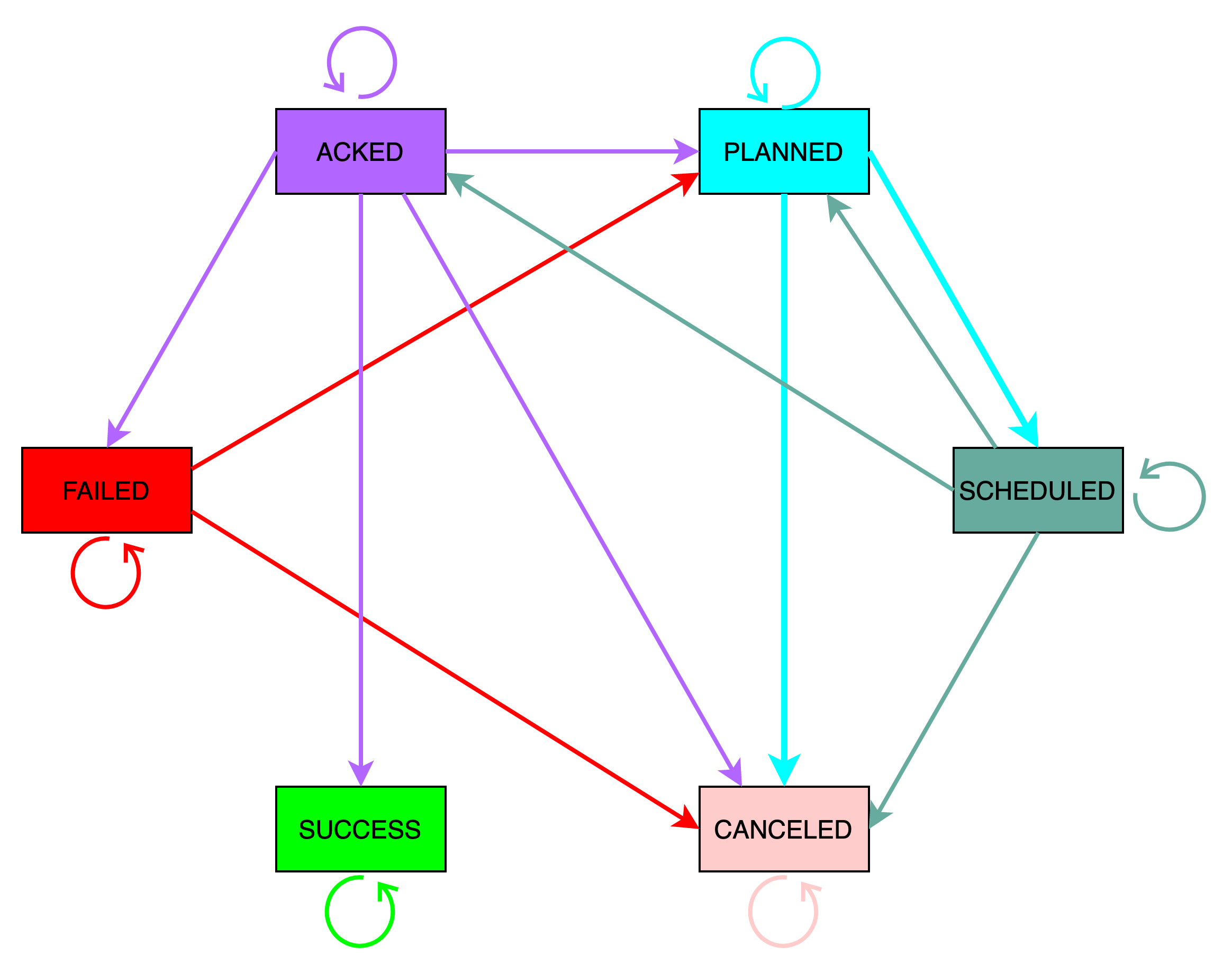
包含6个状态
任务执行
通过OptimizerExecutor.executeTask执行任务,具体逻辑如下图所示:
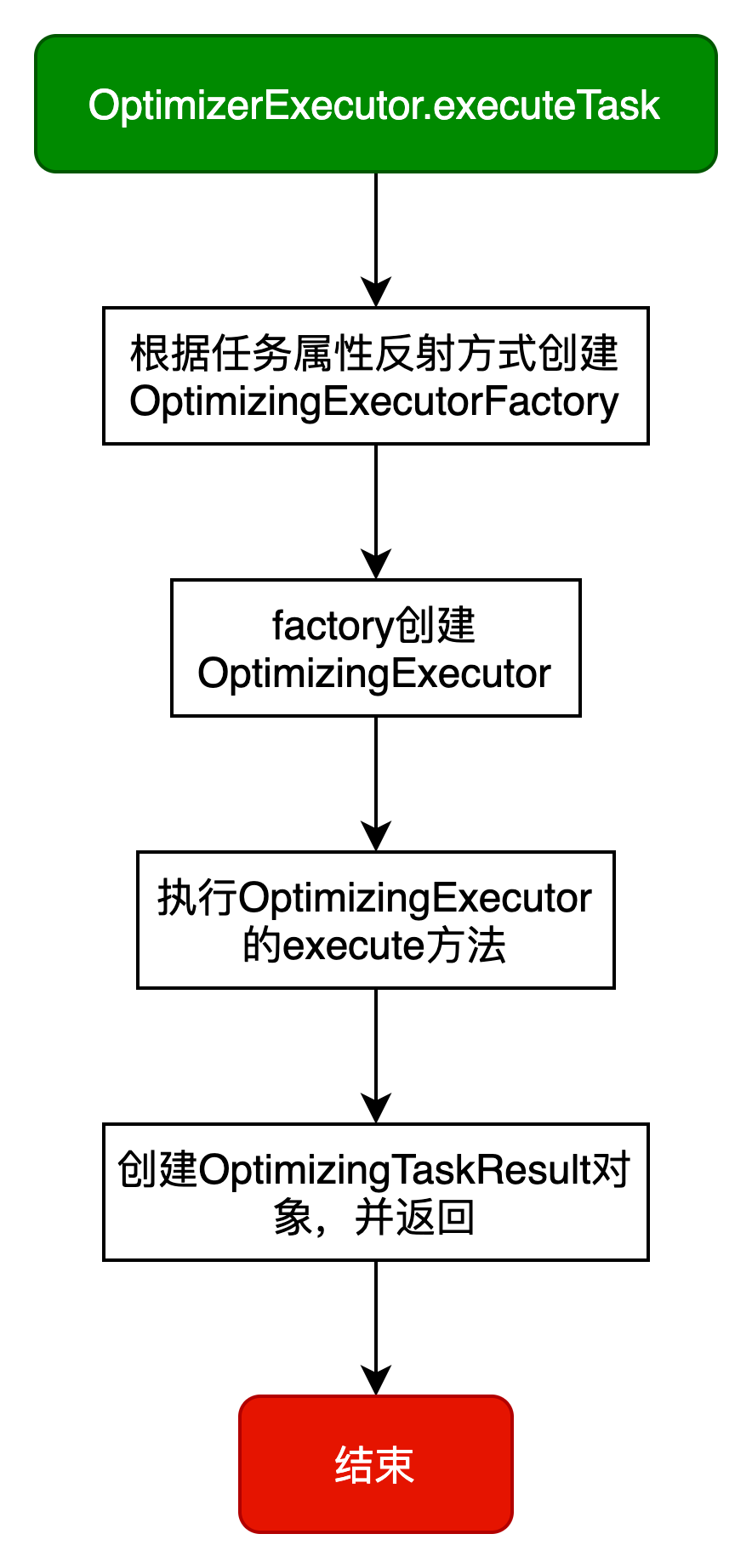
OptimizingExecutor对应的是优化逻辑。