KafkaProducer是kafka最重要的几个api之一。
1.KafkaProducer类结构
我们通过KafkaProducer中的属性链路来解析KafkaProducer的类结构。
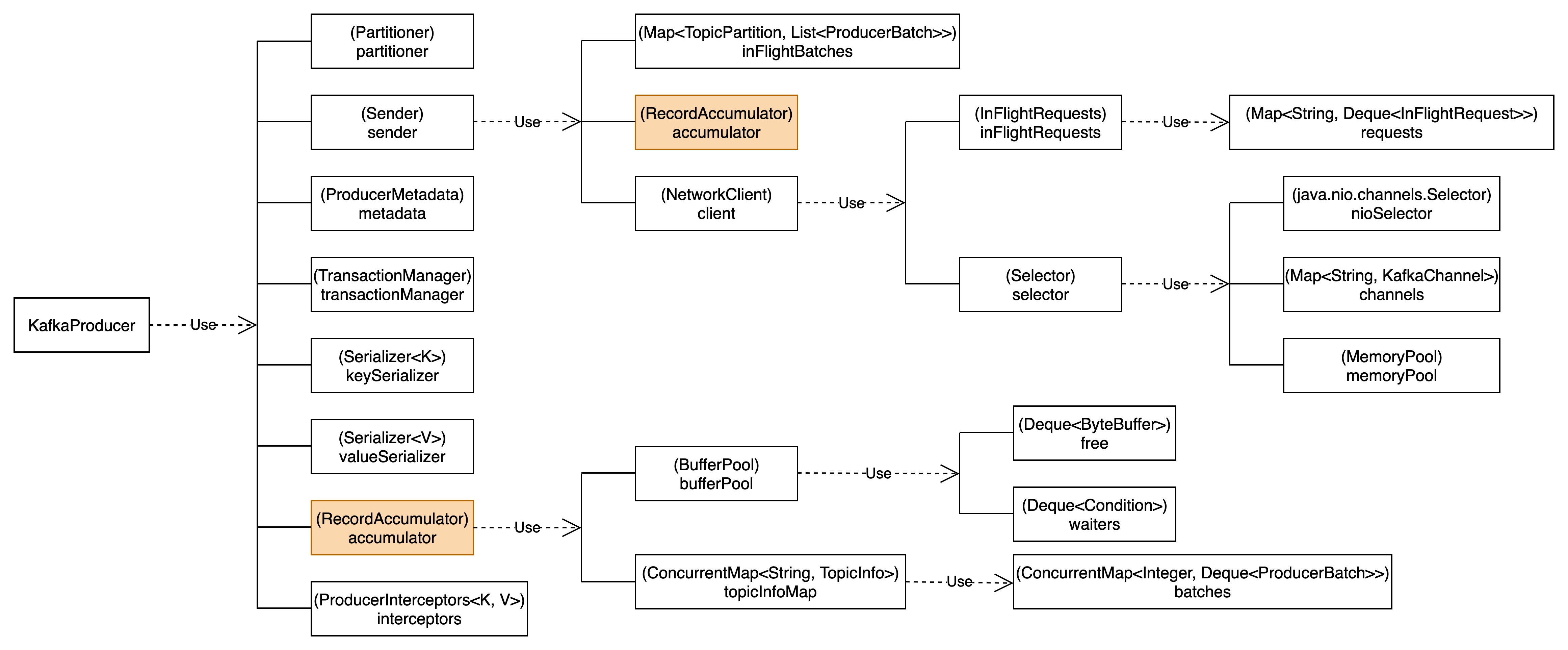
属性链路对我们解析KafkaProducer的消息生产过程十分重要。
2.KafkaProducer线程模型
KafkaProducer进程中包含两个重要的线程:main和producer
2.1.KafkaProducer主线程
主线程名为main,执行过程如下图所示:
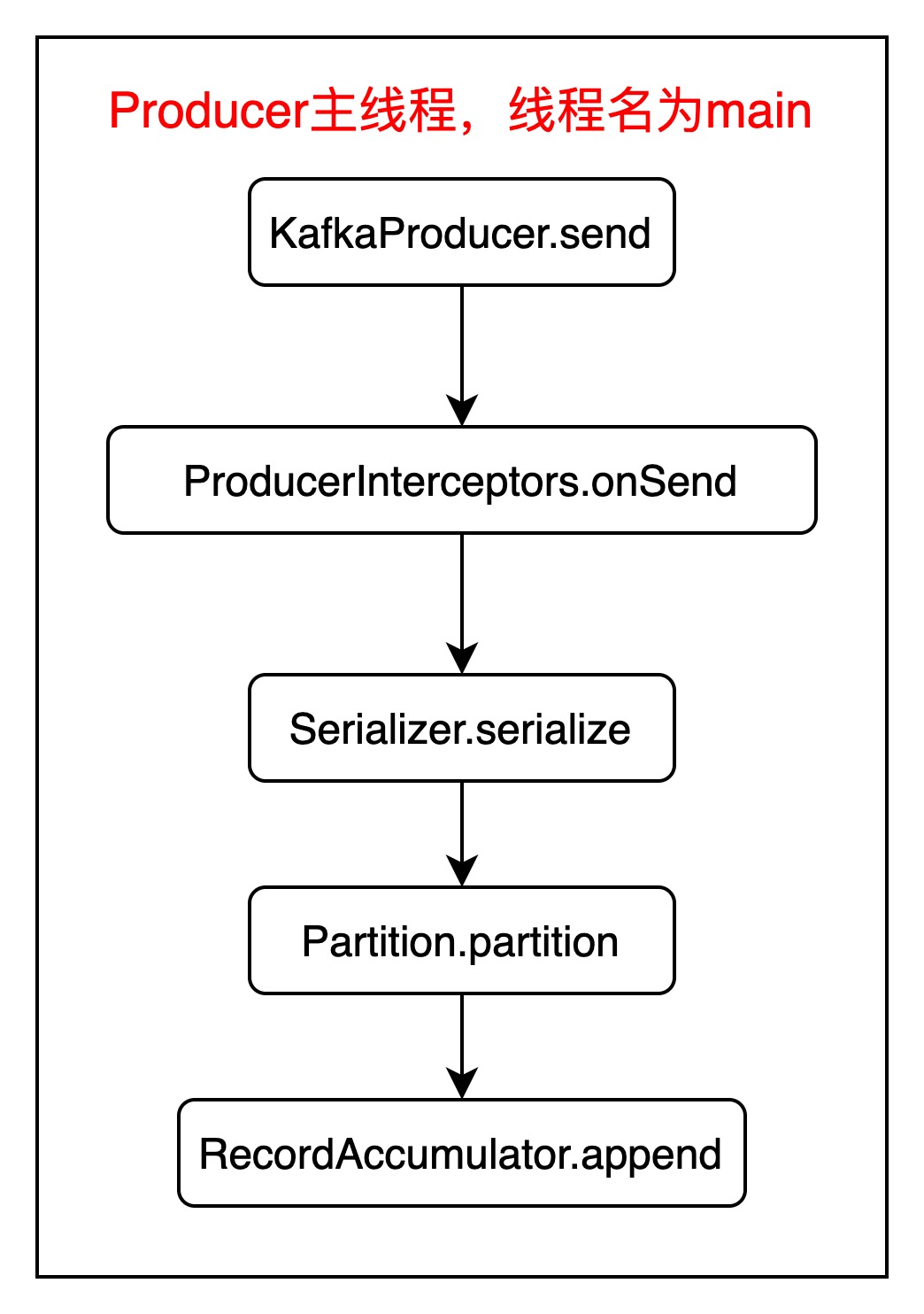
主线程最终把消息写入到了内存中,而内存中的数据需要通过io线程发送给Kafka Broker。
2.2.KafkaProducer IO线程
线程名前缀为kafka-producer-network-thread,IO线程执行过程如下图所示:
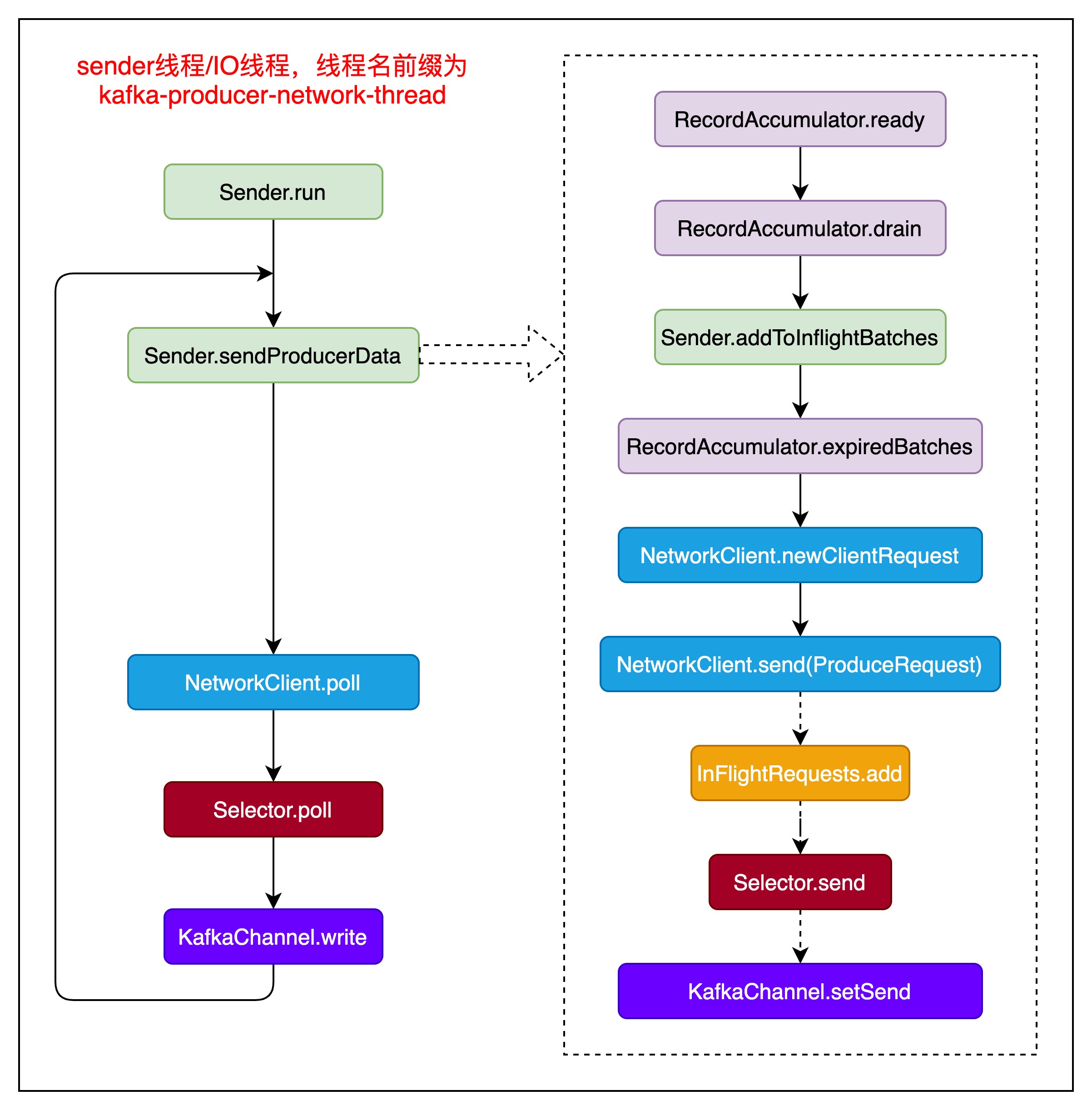
主要通过Sender来完成,kafka自身通过socket编程,以NIO方式实现对数据的发送。
KafkaProducer性能模型
KafkaProducer性能模型主要包含以下机制。
背压机制
当生产者的发送速率超过Broker的接收速率,或者网络拥塞时,生产者内部的缓冲区可能会填满。此时,生产者会根据buffer.memory设定的最大内存限制,暂停从应用程序接收新消息,直到缓冲区中的消息被发送出去,腾出足够的空间,这种机制称为背压控制,它可以防止生产者无限制地占用内存,导致系统资源耗尽。
背压机制主要涉及以下一个参数。
buffer.memory
producer端可缓存消息的最大字节数,默认值为33554432,表示32MB。
如果记录发送到broker的速率比记录写入缓存的速率小,producer会处于block状态,如果超过max.block.ms(默认值1分钟),就会抛异常。
这个配置应当基本接近producer可用的内存,小于producer进程的Xmx。但是这个配置并不是一个严格的边界值,因为数据压缩以及发送请求也需要一定的内存空间。
Producer批量机制
主要涉及以下两个参数
batch.size
批量的大小,一批数据的字节数,默认是16KB。如果此值为0,则禁止批量机制,消息会一条一条发送。
为了减少请求发送次数,Producer会尽可能批量发送消息到Broker,这提升了客户端和服务端的性能。
当一个批次的数据大于此值时,这个批次不会接收新的消息,会被发送到缓冲或Broker。
一个Producer可能同时会有多个batches,每个batch对应一个分区。
小的batch.size值会使批量发送变频繁,降低吞吐量。
而大的batch.size值会造成对内存资源的浪费,因为Producer总是会提前申请到batch.size的缓冲区用于接收持续的消息。
注意,当前参数设置了批量的下限。如果当前批量的大小小于此值,则需要根据linger.ms参数来确定是否发送到缓冲区或Broker。
linger.ms
如果一个批量迟迟没有达到batch.size的大小,sender会等待linger.ms设置的时间,到了后,就会发送数据。单位是毫秒,默认为0,表示没有延迟。
Producer会把消息请求聚合成一个批量请求。
通常,在较低负载情况下,消息到达的效率比发送的效率要低。但在一些场景中,即使是中等的压力,客户端也想降低请求的数量。这个配置就可以满足这种需求,通过增加延迟来实现,也就是不立刻发送消息,producer会等待linger.ms的时间然后把批量请求发送出去。这类似于TCP中的nagle算法。
这个配置只是确定了等待的上限,一旦某个分区的批量请求达到batch.size,不管linger.ms是多少,这个请求还是会被立刻发送。但是,如果某个分区的批量请求迟迟打不到batch.size,producer等待linger.ms后,仍然会把这个批量请求发送出去。
如果把linger.ms设置为5,我们可能降低发送请求速率,但这里就会导致消息有最大5ms的延迟,对消息的实时性是个挑战。
max.request.size
一个请求的最大字节数,默认为1048576,表示1MB。
批量机制还需要注意这个参数,因为批量请求的大小也是不能超过max.request.size配置值的,这里比较的是未被压缩的请求大小。
Socket Buffer
这个属于网络层面的缓存,可以在客户端设置,也可以在服务端设置。
kafka client通用参数
可以在connector、consumer和producer中设置,主要有以下两个参数
send.buffer.bytes
发送数据时,配置TCP发送缓冲大小,和SO_SNDBUF一样。默认131072,表示128KB。如果设置为-1,表示使用操作系统SO_SNDBUF默认值。
receive.buffer.bytes
接收数据时,配置TCP接收缓冲大小,可用SO_RCVBUF表示。默认32768,表示32KB。如果设置为-1,表示使用操作系统SO_RCVBUF默认值。
Kafka Server端参数
需要在KafkaBroker的配置文件server.properties中设置,有三个参数:
socket.send.buffer.bytes
创建Socket时,SO_SNDBUF参数值。默认102400,表示100KB。如果设置为-1,表示使用操作系统层面发送缓冲大小配置。
socket.receive.buffer.bytes
服务端Socket缓冲大小SO_RCVBUF。默认102400,表示100KB。。如果设置为-1,表示使用操作系统SO_SNDBUF默认值。
replica.socket.receive.buffer.bytes
副本同步数据时创建的socket接收缓冲大小。默认为65536,表示64KB。
压缩机制
如果配置了compression.type参数,生产者在发送消息批次之前对其进行压缩。这不仅可以减少网络传输的数据量,降低带宽消耗,还能进一步利用批量发送的优势,因为压缩通常对大批量数据的效果更好。
compression.type
compression.type可以在服务端、topic、producer端进行设置。
服务端配置
为指定的topic设置压缩类型,可选值有uncompressed、zstd、lz4、snappy、gzip、producer六种,默认值为producer,表示使用producer端的配置。当配置为uncompressed时,不会对写入磁盘的数据进行压缩。
topic配置
可以为topic设置compression.type参数,含义与服务端配置一致。
producer端配置
producer端设置了此参数后,生产的数据都会在压缩后发送给Broker,可选值有none、gzip、snappy、lz4、zstd共五种,默认none,表示不压缩。
需要注意的是,压缩是对整体批量数据的压缩,批量的大小会影响到压缩的比率,一般来说,更大的批量意味着更高的压缩比率。
Produce过程源码解析
基于Kafka-3.9.0源码解析Produce过程。
整个Produce过程分为以下几个部分。
Producer初始化
过程如下所示:
KafkaProducer(ProducerConfig config) {
// 从配置中获取事务id
String transactionalId = config.getString(ProducerConfig.TRANSACTIONAL_ID_CONFIG);
// 从配置中获取客户端id编号
this.clientId = config.getString(ProducerConfig.CLIENT_ID_CONFIG);
// 初始化监控
List<MetricsReporter> reporters = CommonClientConfigs.metricsReporters(clientId, config);
// 初始化分区器
this.partitioner
// 初始化拦截器列表
List<ProducerInterceptor<K, V>> interceptorList
// 初始化事务管理器
this.transactionManager = configureTransactionState(config);
// 初始化消息累积器,accumulator负责将消息缓存并组装成批次
this.accumulator = new RecordAccumulator()
// 初始化生产者元数据管理器,metadata用于获取Kafka集群的元数据信息,如Topic分区分布、Broker地址
this.metadata
// 初始化消息发送器,sender专门负责将批次消息发送到Broker
this.sender = newSender()
this.ioThread = new KafkaThread(ioThreadName, this.sender, true);
// 启动发送线程
this.ioThread.start();
}调用send方法发送消息
通过KafkaProducer类的send方法可向topic生产消息,send执行过程如下所示:
org.apache.kafka.clients.producer.KafkaProducer#send(ProducerRecord<K, V> record, Callback callback)
// 按消息发送
KafkaProducer.doSend(record, callback)
// 阻塞获取元数据,直到超时,超时时间为max.block.ms,默认60秒
waitOnMetadata(record.topic(), record.partition(), nowMs, maxBlockTimeMs);
// 对key进行序列化
byte[] serializedKey = keySerializer.serialize(record.topic(), record.headers(), record.key());
// 对value进行序列化
byte[] serializedValue = valueSerializer.serialize(record.topic(), record.headers(), record.value());
// 分区器为消息分配分区编号
int partition = partition(record, serializedKey, serializedValue, cluster);
// 消息收集器收集消息
RecordAccumulator.RecordAppendResult result = accumulator.append(record, partition, serializedKey, serializedValue)
if (result.abortForNewBatch)
// 需要开启新的批次再往消息收集器发送
result = accumulator.append(record, partition, serializedKey, serializedValue)
if (result.batchIsFull || result.newBatchCreated)
// 批次已满,或者说新的批次刚创建,则唤醒sender
Sender.wakeup();
KafkaClient.wakeup() // 实际是NetworkClient
org.apache.kafka.common.network.Selector#wakeup
java.nio.channels.Selector#wakeup
return result.future;往消息收集器添加消息
RecordAccumulator是生产者实现高性能写的关键组件,其核心是缓存信息并构建消息批次。RecordAccumulator内部维护了一个Deque<ProducerBatch>队列,用于存储待发送的批次,通过BufferPool管理内存缓冲区,避免频繁的内存分配与释放。
RecordAccumulator的append方法往对应的队列中添加消息,执行过程如下所示:
org.apache.kafka.clients.producer.internals.RecordAccumulator#append(String topic, int partition, long timestamp, byte[] key, byte[] value, Header[] headers, AppendCallbacks callbacks, long maxTimeToBlock, boolean abortOnNewBatch, long nowMs, Cluster cluster)
// 当前正在append的消息数量加一,同一个生产者被多个线程调用生产消息
appendsInProgress.incrementAndGet();
ByteBuffer buffer = null;
while (true) // 无限循环
// 计算有效分区号,如果方法调用时的partition为-1,则将最近发送到broker批次对应的分区作为有效分区号,否则使用方法调用时的partition
int effectivePartition
// 检查有效分区号是否有对应的消息批次,没有则新增
Deque<ProducerBatch> dq = topicInfo.batches.computeIfAbsent(effectivePartition, k -> new ArrayDeque<>());
synchronized (dq) // 对dq加锁,防止多个线程同时往一个topic-partition中添加消息
// 尝试添加消息
RecordAppendResult appendResult = tryAppend(timestamp, key, value, headers, callbacks, dq, nowMs);
// 获取最后一个消息批次
ProducerBatch last = deque.peekLast();
if (last != null)
// 尝试往消息批次添加消息
FutureRecordMetadata future = last.tryAppend
int appendedBytes = last.estimatedSizeInBytes() - initialBytes;
// 当dq队列中的数量大于1,或者最后一个批次已满,则表示需要通过网络线程将消息发送到broker
return new RecordAppendResult(future, dq.size() > 1 || last.isFull(), false, false, appendedBytes);
if (appendResult != null)
表示添加成功
if (abortOnNewBatch)
return new RecordAppendResult(null, false, false, true, 0);
if (buffer == null)
// 计算缓冲区大小,当前消息量与batch.size之间取最大值
int size = Math.max(this.batchSize, AbstractRecords.estimateSizeInBytesUpperBound(maxUsableMagic, compression.type(), key, value, headers));
// 阻塞式申请缓冲区大小,
buffer = free.allocate(size, maxTimeToBlock);
synchronized (dq)
// 判断是否跟上一次的添加的分区号一致,如果一致,则continue进入下一轮循环
// 新增ProducerBatch
RecordAppendResult appendResult = appendNewBatch
// 更新最近一次新增ProducerBatch对应的分区号
topicInfo.builtInPartitioner.updatePartitionInfo()
return appendResult;
append方法的最后需要进行资源释放
free.deallocate(buffer);
appendsInProgress.decrementAndGet();Sender提取ProducerBatch
Sender线程负责从RecordAccumulator中取出满足发送条件的ProducerBatch,并通过NetworkClient将消息发送到Broker。
org.apache.kafka.clients.producer.internals.Sender#run
if (transactionManager != null)
// 事务管理器不为空
transactionManager.setPoisonStateOnInvalidTransition(true);
while (running)
// 线程运行状态,则进入无限循环
runOnce()
while (!forceClose && ((this.accumulator.hasUndrained() || this.client.inFlightRequestCount() > 0) || hasPendingTransactionalRequests()))
// 我们停止线程接收多余请求后,可能还会有一些正在处理的请求或者在收集器未完成的请求,亦或是某些在等待响应的请求,需要将这些处理完线程才能结束
runOnce()
while (!forceClose && transactionManager != null && transactionManager.hasOngoingTransaction())
// 终止事务管理器后,如果还有些commit或abort的事务没有进入到事务管理器的队列,则需要将这些食物处理完才能结束
if (!transactionManager.isCompleting())
// 如果事务未结束,则启动终止事务
transactionManager.beginAbort()
runOnce()
if (forceClose)
// 停止事务管理器
transactionManager.close()
// RecordAccumulator终止未完成的批量
accumulator.abortIncompleteBatches()
// 终止网络连接
this.client.close()runOnce()方法将启动一次发送消息的发送,执行过程如下
org.apache.kafka.clients.producer.internals.Sender#runOnce
// 执行一次发送任务
if (transactionManager != null)
// 进行事务处理
long currentTimeMs = time.milliseconds();
// 准备需要发送的消息
long pollTimeout = sendProducerData(currentTimeMs);
// 获取元数据
metadataSnapshot = metadata.fetchMetadataSnapshot()
// 获取待发送的分区数据
result = this.accumulator.ready(metadataSnapshot
if (!result.unknownLeaderTopics.isEmpty())
// 如果某些分区的leader为-1,则强制进行对应topic的元数据更新
this.metadata.requestUpdate(false);
// 移除所有无法发送消息的节点
iter = result.readyNodes.iterator()
while (iter.hasNext())
node = iter.next()
if (!this.client.ready(node, now))
// 节点无法连接,移除改节点
this.accumulator.updateNodeLatencyStats(node.id(), now, false);
// 创建Produce请求
// 获取所有待发送的消息批次,按分区进行分组
Map<Integer, List<ProducerBatch>> batches = this.accumulator.drain()
addToInflightBatches(batches);
// 计算超时时间
long pollTimeout
// 发送请求
sendProduceRequests(batches, now);
// 针对每个broker,分别发送消息
for (nodeId : batches.entrySet())
sendProduceRequest(nodeId, batches.get(nodeId))
// 事务处理
// 构建ProduceRequest
ProduceRequest.Builder requestBuilder
// 构建回调函数
RequestCompletionHandler callback
// 构建客户端请求,acks起作用就在此处,如果acks不为0,表示需要等待响应消息,否则发送完成即可。
ClientRequest clientRequest = NetworkClient.newClientRequest(nodeId, requestBuilder, callback)
// 发送请求
NetworkClient.send(clientRequest, now);
return pollTimeout;
// 通过socket发送请求,并等待响应,带有超时时间
NetworkClient.poll(pollTimeout, currentTimeMs);NetworkClient发送消息
NewworkClient基于Java NIO实现非阻塞网络通信,通过Selector管理网路连接和I/O操作。
org.apache.kafka.clients.NetworkClient#send
RequestHeader header = clientRequest.makeHeader(request.version());
Send send = request.toSend(header);
selector.send(new NetworkSend(clientRequest.destination(), send));
String connectionId = send.destinationId();
KafkaChannel channel = openOrClosingChannelOrFail(connectionId);
channel.setSend(send);Selector会不断轮训检查网络连接状态,当连接可写时,将数据写入SocketChannel,实现高效的网络传输。