创建Catalog到生成表优化记录
使用amoro的第一步,就是需要配置资源组和注册catalog,catalog表示数据湖的元数据管理器。
创建资源组
Amoro中通过ResourceGroup类表示资源组的抽象,所有的优化器都会在某个资源组内运行。
资源组可以是yarn的队列,也可以是k8s集群的某个namespace。
ResourceGroup类的定义如下所示:
public class ResourceGroup {
private String name;
private String container;
private Map<String, String> properties;
}资源组有三个重要属性:name表示资源组名称,可任意取;container表示优化器了行,与ams.containers配置列表的名称对应;properties表示此资源组的属性,可根据实现进行个性化配置。
一个Amoro实例中,资源组的name是唯一的,不能重复,且名称需满足一定的正则表达式。
ResourceGroup的管理在org.apache.amoro.resource.ResourceManager类中,默认是org.apache.amoro.server.resource.DefaultOptimizerManager。
ResourceGroup创建通过接口/optimize/resourceGroups/create来完成,具体实现在org.apache.amoro.server.dashboard.controller.OptimizerGroupController#createResourceGroup方法中,创建资源组的动作一般需要在Amoro-WebUI中完成,创建完成后,数据库的resource_group表中会新增一条记录。
资源组创建后,在创建Catalog时,需选择对应的资源组,以确定此catalog下的优化任务提交到那个ResourceGroup。
创建catalog
创建catalog是amoro server提供的接口,用于注册数据湖目录。接口定义为“/catalogs POST”。后端接口处理如下:
// 创建catalog
org.apache.amoro.server.dashboard.controller.CatalogController#createCatalog
// 将请求信息转化为CatalogRegisterInfo实例(注册信息)
CatalogRegisterInfo info = ctx.bodyAsClass(CatalogRegisterInfo.class);
// 校验注册信息
validateCatalogRegisterInfo(info);
// 认证配置不能为null
// 存储配置不能为null
// catalog属性不能为null
// 表属性不能为null
// 表格式不能为null
// catalog类型是否支持
// catalog必备属性必须存在
catalogService.catalogExist(info.getName())
// 检查catalog是否已存在,如果已存在则抛异常new RuntimeException("Duplicate catalog name!")
// 构建catalog_meta表记录
CatalogMeta catalogMeta = constructCatalogMeta(info, null);
// 构建catalogProperties,将tableProperties和properties进行聚合,tableProperties中的属性key加“table.”前缀
catalogMeta.setCatalogProperties
// 添加属性“table.self-optimizing.group”
catalogMeta.putToCatalogProperties
// 添加属性
catalogMeta.getCatalogProperties().put("table-formats", tableFormats);
// 填充认证配置,支持simple、kerberos、ak/sk三种不同的认证方式
fillAuthConfigs2CatalogMeta(catalogMeta, info.getAuthConfig(), oldCatalogMeta, storageType);
// 填充存储配置,文件的内容保存在platform_file中,amoro webui在创建catalog时,需要上传hdfs-site.xml、core-site.xml、hive-site.xml等文件。
catalogMeta.setStorageConfigs(metaStorageConfig);
return catalogMeta;
// 创建catalog
catalogService.createCatalog(catalogMeta);
// 根据catalogName检查catalog是否已存在,如果存在则抛AlreadyExistsException异常
catalogExist(catalogMeta.getCatalogName())
// 填充catalog属性
fillCatalogProperties(catalogMeta);
// 对于hive catalog,需要添加“ams.uri”和“clients”属性
// 构建ServerCatalog实例
ServerCatalog catalog = CatalogBuilder.buildServerCatalog(catalogMeta, serverConfiguration);
// 将catalog记录持久化到数据库的catalog_metadata表
CatalogMetaMapper.insertCatalog(catalog.getMetadata())
// 将catalog缓存到服务内存中
serverCatalogMap.put(catalogMeta.getCatalogName(), catalog);
// 成功返回
ctx.json(OkResponse.of(""));存储配置需要从platform_file表中读取。
存储配置文件
amoro webui注册catalog的页面中,需要我们选择存储类型,并上传对应存储的配置文件,上传存储文件是通过“/files POST”接口来实现的。后端接口处理如下:
org.apache.amoro.server.dashboard.controller.PlatformFileInfoController#uploadFile
// 读取文件内容
byte[] bytes = IOUtils.toByteArray(bodyAsInputStream);
// 如果是xml文件,则进行文件校验
// 将文件内容转换为base64编码
String content = Base64.getEncoder().encodeToString(bytes);
Integer fid = platformFileInfoService.addFile(name, content);
org.apache.amoro.server.persistence.mapper.PlatformFileMapper#addFile
持久化到platform_file表
Map<String, String> result = new HashMap<>();
result.put("id", String.valueOf(fid));
result.put("url", "/api/ams/v1/files/" + fid);
// 返回文件id
ctx.json(OkResponse.of(result));存储配置文件最终保存为platform_file表中的一条记录。
优化表信息生成
注册catalog后,catalog_metadata表有信息,接下来是通过定时扫描任务生成table_identifier记录,表示需要被优化的表。
在AmoroServiceContainer启动时,会往定时器注册一个探测器任务,过程如下所示:
org.apache.amoro.server.AmoroServiceContainer#main
AmoroServiceContainer service = new AmoroServiceContainer();
service.startService();
tableService = new DefaultTableService(serviceConfig, catalogManager);
tableService.initialize();
// 检查当前实例未被初始化,即未调用initialize方法。如果已被初始化,则抛IllegalStateException异常
// 从table_runtime表查询正在优化的表的记录
List<DefaultTableRuntime> tableRuntimes
// 对正在优化的表执行初始化操作
org.apache.amoro.server.table.RuntimeHandlerChain#initialize(tableRuntimes)
// 初始化优化表探测器的线程池tableExplorerExecutors,旨在扫描catalog中有需要被优化的表,并记录到table_identifier表中
tableExplorerExecutors = new ThreadPoolExecutor()
// 线程大小为refresh-external-catalogs.thread-count,默认10
// 队列大小为refresh-external-catalogs.queue-size,默认100万
// 线程名为"table-explorer-executor-%d"
tableExplorerScheduler.scheduleAtFixedRate(this::exploreTableRuntimes)
// 周期调度exploreTableRuntimes方法,周期配置为refresh-external-catalogs.interval,默认3分钟
// 标记初始化完成
initialized.complete(true);org.apache.amoro.server.table.DefaultTableService#exploreTableRuntimes会被调度器周期调度,任务执行过程如下所示:
org.apache.amoro.server.table.DefaultTableService#exploreTableRuntimes
// 从catalog_metadata表中查询所有的catalog
List<ServerCatalog> externalCatalogs
// 获取所有catalog的名称
List<String> externalCatalogNames
// 遍历externalCatalogs中的每个catalog
for (ServerCatalog serverCatalog : externalCatalogs) {
// 如果是internal类型
exploreInternalCatalog(serverCatalog)
// 如果是external类型
exploreExternalCatalog(serverCatalog)
// 查询serverCatalog下所有的库表信息。如果是iceberg表,则调用iceberg-api包中的类和方法。注意过滤时,库名需要符合catalog的database-filter属性值(正则表达式),表名需要符合catalog的table-filter属性值(正则表达式)
// 生成table_identifier表记录。
Set<TableIdentity> tableIdentifiers
// 从table_identifier表中查询serverCatalog正在进行优化的表,即已生成记录的表
Map<TableIdentity, ServerTableIdentifier> serverTableIdentifiers
List<CompletableFuture<Void>> taskFutures = Lists.newArrayList();
// 查找tableIdentifiers中,不存在于serverTableIdentifiers中的记录,并生表同步任务CompletableFuture
Sets.difference(tableIdentifiers, serverTableIdentifiers.keySet()).forEach(tableIdentity ->
taskFutures.add(
CompletableFuture.runAsync(
org.apache.amoro.server.table.DefaultTableService#syncTable(serverCatalog, tableIdentity)
)
)
)
// 查找serverTableIdentifiers的所有key中,不存在于tableIdentifiers的记录,并将此记录从serverTableIdentifiers中移除
Sets.difference(serverTableIdentifiers.keySet(), tableIdentifiers).forEach(tableIdentity ->
taskFutures.add(
CompletableFuture.runAsync(
org.apache.amoro.server.table.DefaultTableService#disposeTable(serverTableIdentifiers.get(tableIdentity));
)
)
)
// 任务串行执行
taskFutures.forEach(CompletableFuture::join);
}表同步过程在org.apache.amoro.server.table.DefaultTableService#syncTable方法中定义,执行过程如下:
org.apache.amoro.server.table.DefaultTableService#syncTable
// 调用ExternalCatalog#syncTable方法
org.apache.amoro.server.catalog.ExternalCatalog#syncTable
// 生成table_identifier表记录对象
ServerTableIdentifier tableIdentifier
// 将table_identifier表记录持久化到数据库
TableMetaMapper.insertTable(tableIdentifier)
// 从table_identifier表中查询对应的表记录
ServerTableIdentifier tableIdentifier = TableMetaMapper.selectTableIdentifier
// 将查询的结果执行添加操作
triggerTableAdded(externalCatalog, tableIdentifier)
// 从catalog加载表
AmoroTable<?> table =catalog.loadTable(……)
// 生成TableRuntime记录,并存入本地缓存
DefaultTableRuntime tableRuntime
tableRuntimeMap.put(serverTableIdentifier.getId(), tableRuntime);
// 触发RuntimeHandlerChain进行表的添加操作
RuntimeHandlerChain#fireTableAdded(tableRuntime)
// 如果以上操作发生异常,则进行回退
org.apache.amoro.server.table.DefaultTableService#revertTableRuntimeAdded至此,将ServerTableIdentifier实例顺利持久化到数据库中,生成了一个新的待优化表的记录。
表优化任务调度过程
表优化的调度还得从AMS服务启动开始讲起。
AMS服务启动
Amoro是一个后台服务,通过调度的方式生成和启动优化任务。
后台服务的启动入口在AmoroServiceContainer类中,启动过程如下:
org.apache.amoro.server.AmoroServiceContainer#main
// 初始化AmoroServiceContainer实例
service = new AmoroServiceContainer();
//添加shutdown hook
addShutdownHook(new Thread(() -> service.dispose())
// 阻塞等待进入Leader状态
service.waitLeaderShip();
// 启动AMS
service.startService();
tableService = new DefaultTableService
// 初始化DefaultOptimizingService实例
optimizingService = new DefaultOptimizingService
tableHandlerChain = new TableRuntimeHandlerImpl();
// optimizingService.getTableRuntimeHandler()返回optimizingService实例中的tableHandlerChain属性
tableService.addHandlerChain(optimizingService.getTableRuntimeHandler())
tableService.initialize()
// 从表table_runtime查询表优化列表
tableRuntimeMetaList = TableMetaMapper.selectTableRuntimeMetas
// 将tableRuntimeMetaList转化为List<TableRuntime> tableRuntimes
// headHandler为optimizingService实例中的tableHandlerChain属性
headHandler.initialize(tableRuntimes)
RuntimeHandlerChain#initialize(tableRuntimes)
TableRuntimeHandlerImpl#initHandler(tableRuntimes)
// 初始化定时器
optimizerMaintainTimer = new Timer("OptimizerMaintainer", true);
// 启动定时任务,延迟时间和实践间隔由optimizer.maintainer-check-interval配置决定,默认是30分钟
optimizerMaintainTimer.schedule(new ResourceMaintainer(), optimizerMaintainInterval, optimizerMaintainInterval);
// 阻塞等待进入Follower状态
service.waitFollowerShip();这里启动了定时器,定时执行ResourceMaintainer中的任务逻辑。
TableRuntimeHandlerImpl初始化
TableRuntimeHandlerImpl主要作用是作为表运行时事件的处理链,负责监听和处理表的各种状态变化,并将这些变化传递给相应的优化队列。
initHandler方法如下
@Override
protected void initHandler(List<DefaultTableRuntime> tableRuntimeList) {
LOG.info("OptimizerManagementService begin initializing");
loadOptimizingQueues(tableRuntimeList);
optimizerKeeper.start();
optimizingConfigWatcher.start();
LOG.info("SuspendingDetector for Optimizer has been started.");
LOG.info("OptimizerManagementService initializing has completed");
}loadOptimizingQueues方法用于加载优化队列,该方法的执行过程包括:
(1)数据准备阶段:从数据库获取所有资源组(ResourceGroup);获取所有优化器实例(OptimizerInstance);将表运行时按组名分组。
(2)队列创建阶段:为每个资源组创建 OptimizingQueue 实例;将队列存储在 optimizingQueueByGroup 映射中;注册所有已存在的优化器实例。
OptimizerKeeper是一个优化器守护线程,使用延迟队列监控优化器心跳,自动清理过期优化器,处理任务重试逻辑
OptimizingConfigWatcher是一个配置观察器线程,定期检查资源组配置变化,动态调整优化队列配置,确保系统配置一致性。
scaleOutOptimizer启动优化器
scaleOutOptimizer是org.apache.amoro.server.dashboard.controller.OptimizerGroupController中的方法,用于启动优化器,也是对外提供的接口,用于webui页面启动对应的优化器。
org.apache.amoro.server.dashboard.controller.OptimizerGroupController#scaleOutOptimizer启动优化器
String optimizerGroup // 资源组名称
JSONObject optimizerConf // 优化器配置
// 根据资源组名称查询resource_group表,获取资源组记录
resourceGroup = optimizerManager.getResourceGroup(optimizerGroup)
Resource resource = new Resource.Builder().build()
// 从optimizerConf获取并发度
parallelism = optimizerConf.getIntValue("parallelism");
// 生成资源抽象
resource = new Resource.Builder().build()
// 获取ResourceContainer,发送请求
InternalContainers.get(resource.getContainerName()).requestResource(resource)
org.apache.amoro.server.manager.AbstractOptimizerContainer#doScaleOut
// 具体的优化器启动
FlinkOptimizerContainer#doScaleOut(resource)
或KubernetesOptimizerContainer#doScaleOut(resource)
或LocalOptimizerContainer#doScaleOut(resource)
或SparkOptimizerContainer#doScaleOut(resource)
// 将doScaleOut的返回值添加到resource中
resource.getProperties().putAll(startupStats);
// 启动完成后,将resource持久化到resource表中
org.apache.amoro.server.resource.DefaultOptimizerManager#createResource(resource)scaleOutOptimizer主要是扩展一个Container进程,首先将ResourceGroup转化为Resource,然后通过Resource调用对应的ResourceContainer创建Container进程。
容器类型有以下四种
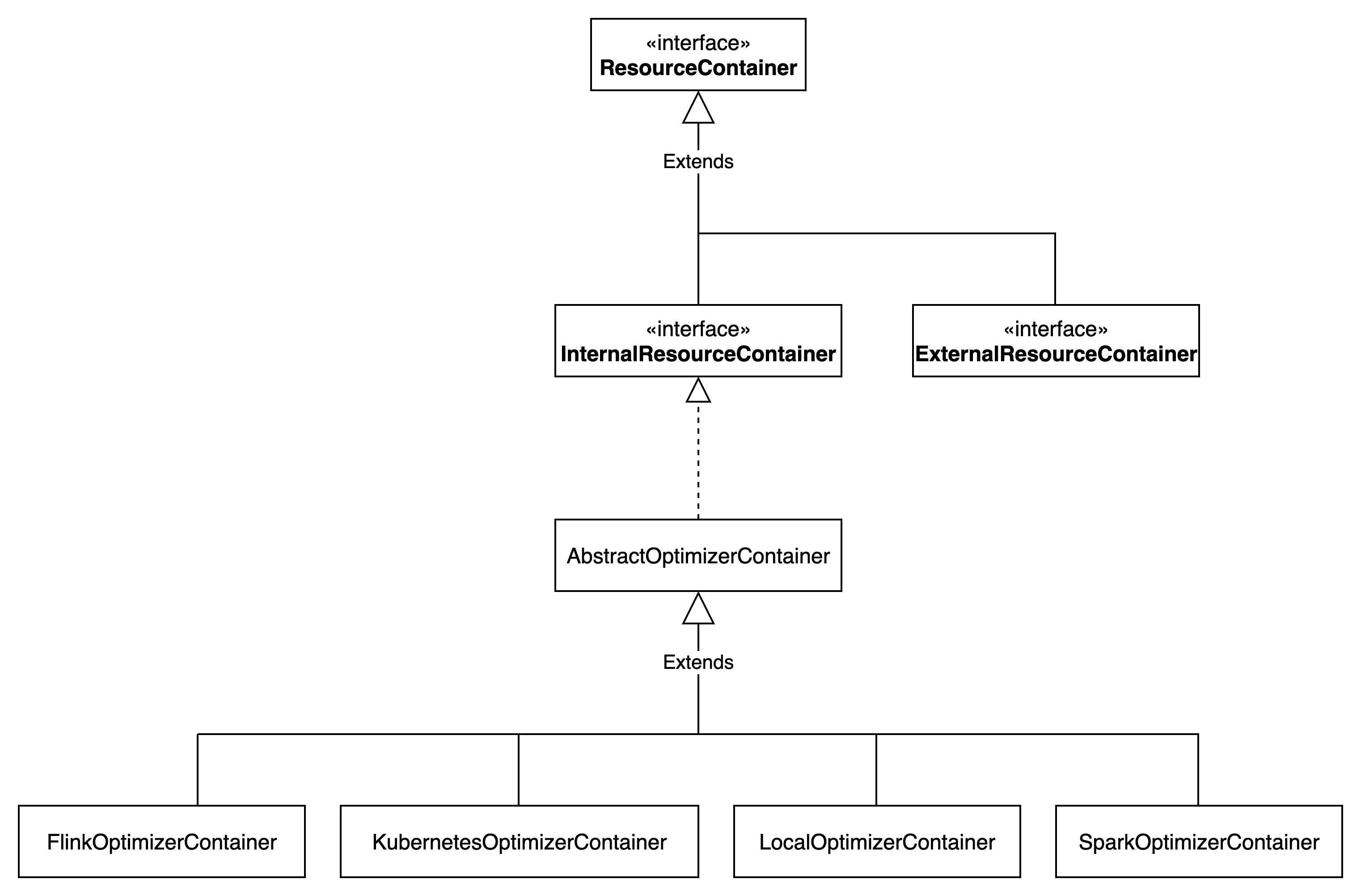
优化器启动后,就是执行优化器的优化逻辑。
优化器及其优化逻辑
Amoro优化器简述
Amoro对表的优化是通过优化器来完成的,目前支持以下优化器:flink优化器、spark优化器、standalone优化器。
Optimizer类型
Optimizer表示不同的优化器类型。
Optimizer的类型如下图所示
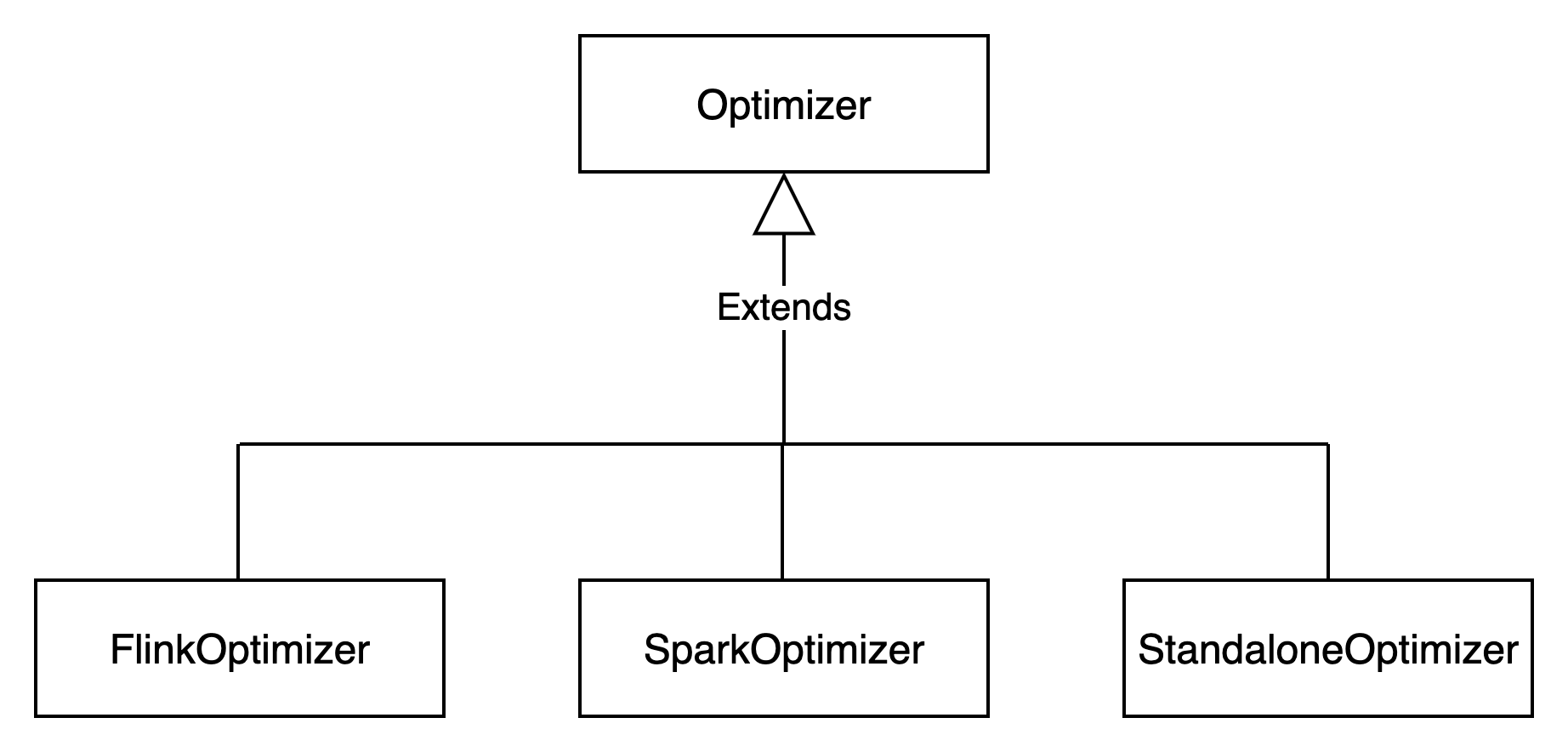
OptimizerExecutor类型
OptimizerExecutor表示优化器执行器,包含优化器的处理逻辑。
OptimizerExecutor的类型如下图所示
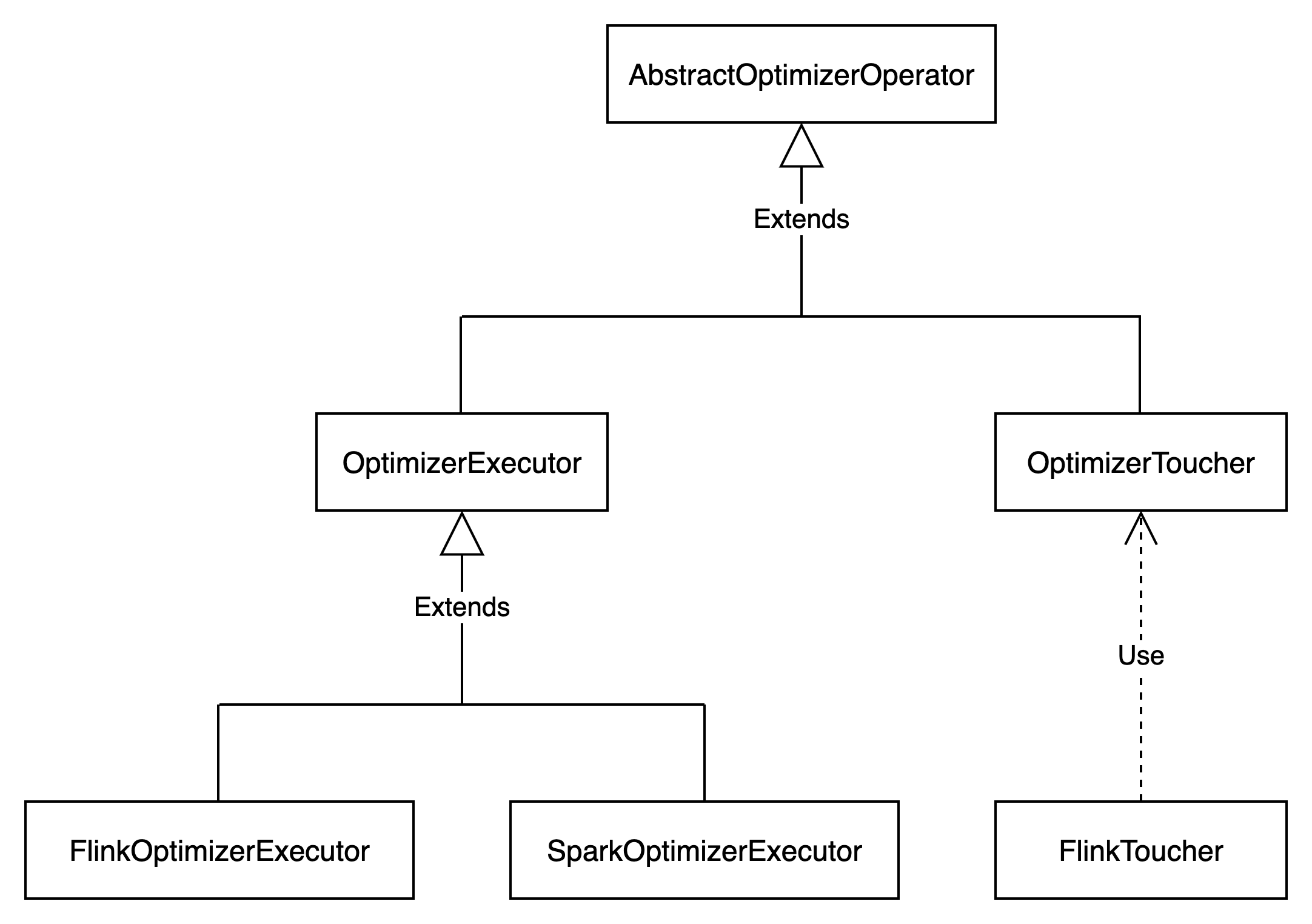
任务的执行在OptimizerExecutor中。
Amoro优化器类结构
Amoro优化器完整类结构如下图所示:
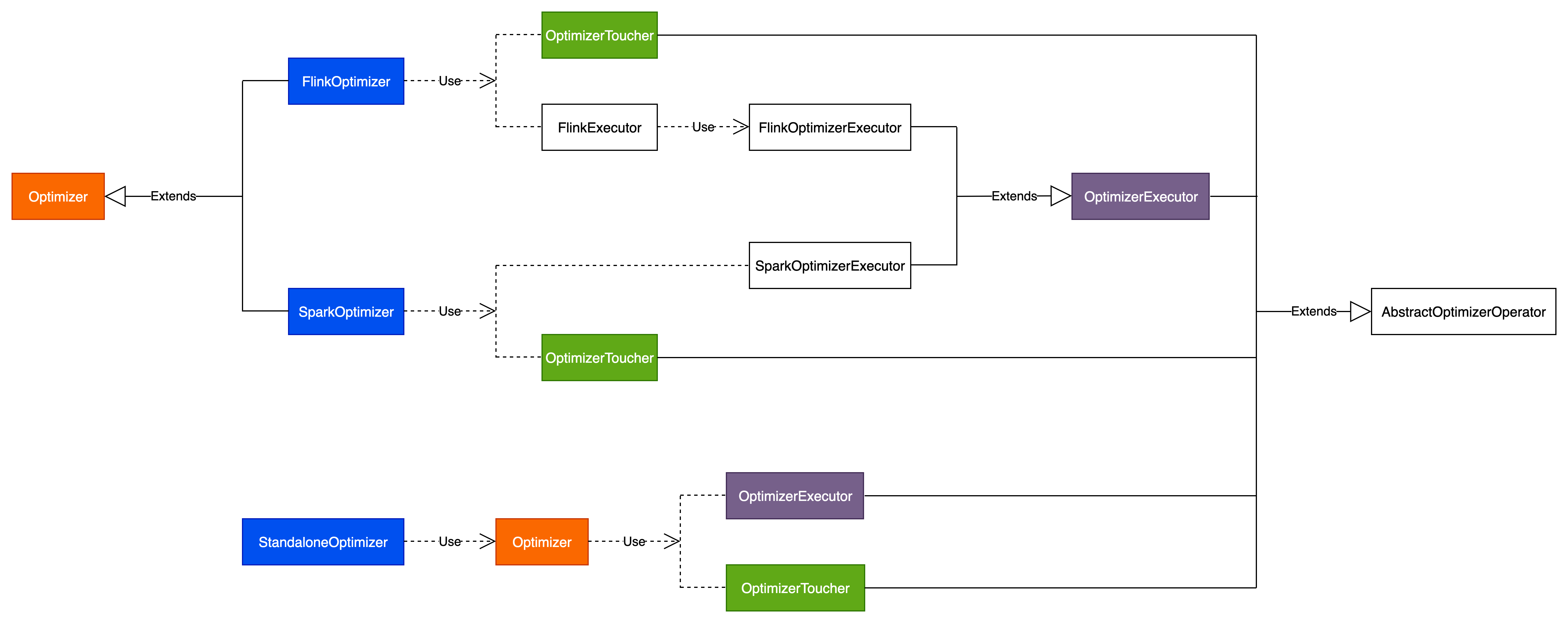
下面分别对这些优化器进行解析。
优化器配置
优化器配置表示启动优化器进程的一些命令行配置,定义在org.apache.amoro.optimizer.common.OptimizerConfig类中,包含以下配置
Flink优化器
跟踪flink优化器的执行过程。
Flink优化器执行入口
Flink优化器进程由org.apache.amoro.server.manager.FlinkOptimizerContainer启动,进程main函数在org.apache.amoro.optimizer.flink.FlinkOptimizer中定义,main函数即为Flink优化器的执行入口,逻辑如下:
org.apache.amoro.optimizer.flink.FlinkOptimizer#main
StreamExecutionEnvironment env
OptimizerConfig optimizerConfig
// 计算优化器内存分配
calcOptimizerMemory(optimizerConfig, env);
// 初始化FlinkOptimizer
Optimizer optimizer = new FlinkOptimizer(optimizerConfig);
env.addSource(new FlinkToucher())
.transform(new FlinkExecutor())
.addSink(new DiscardingSink<>())
// 启动flink任务,指定任务名称
env.execute("amoro-flink-optimizer-{resourceId}")优化器内存计算
calcOptimizerMemory方法计算flink任务所需的内存,逻辑如下。
org.apache.amoro.optimizer.flink.FlinkOptimizer#calcOptimizerMemory(config)
// 获取jobmanager.memory.process.size配置
MemorySize jobMemorySize
// 获取taskmanager.memory.process.size配置
MemorySize taskMemorySize
// jobMemorySize或taskMemorySize为空,表示本地运行,无需计算
if (jobMemorySize == null || taskMemorySize == null) return;
// 获取优化器并发度,由“-p”配置
int parallelism
// 获取taskmanager.numberOfTaskSlots配置
int numberOfTaskSlots
// 计算总内存大小,注意单位一致
int memorySize = jobMemorySize + (parallelism / numberOfTaskSlots) * taskMemorySize;
// 如果parallelism不是numberOfTaskSlots的整数倍,则还需要加一个task的内存
if (parallelism % numberOfTaskSlots != 0) memorySize += taskMemorySize;
config.setMemorySize(memorySize);初始化FlinkOptimizer
初始化FlinkOptimizer实例,并根据优化器并发度初始化FlinkOptimizerExecutor列表
new FlinkOptimizer(optimizerConfig);
// 初始化OptimizerToucher实例
OptimizerToucher toucher
// 根据优化器并发度初始化FlinkOptimizerExecutor列表,每个FlinkOptimizerExecutor表示一个线程,线程号为数字,从0开始
OptimizerExecutor[] executors = new FlinkOptimizerExecutor[config.getExecutionParallel()]
FlinkOptimizer
// 如果资源id不为空,则注册此属性
if (config.getResourceId() != null) {
toucher.withRegisterProperty("resource-id", config.getResourceId());
}Spark优化器
跟踪spark优化器的执行过程。
Spark优化器启动
Spark优化器为org.apache.amoro.optimizer.spark.SparkOptimizer,AMS通过org.apache.amoro.server.manager.SparkOptimizerContainer来启动对应的SparkOptimizer。
// 启动spark优化器
org.apache.amoro.server.manager.SparkOptimizerContainer#doScaleOut
// 构建基础启动命令(spark-submit命令),jar包为plugin/optimizer/spark/optimizer-job.jar,main类为org.apache.amoro.optimizer.spark.SparkOptimizer,可通过“spark-conf.”前缀来设置spark conf的启动参数
String startUpArgs = this.buildOptimizerStartupArgsString(resource);
// 构建环境变量export命令,通过“export.”前缀的key来设置环境变量
String exportCmd = String.join(" && ", exportSystemProperties());
// 构建完整启动命令
String startUpCmd = String.format("%s && %s", exportCmd, startUpArgs);
String[] cmd = {"/bin/sh", "-c", startUpCmd};
// 启动独立的异步进程
Process exec = Runtime.getRuntime().exec(cmd);
// 将启动的applicationId记录到map中
Map<String, String> startUpStatesMap
return startUpStatesMap这里启动了一个新的进程,进程执行入口为org.apache.amoro.optimizer.spark.SparkOptimizer类的main方法。
Spark优化器执行
SparkOptimizer的main函数执行过程如下:
spark优化器为org.apache.amoro.optimizer.spark.SparkOptimizer,main函数为执行入口,当
org.apache.amoro.optimizer.spark.SparkOptimizer#main(args)
// 解析入参,包含并发度、资源名称、ams连接等信息
config = new OptimizerConfig(args);
// 创建SparkSession实例,名称为"amoro-spark-optimizer-{入参id的配置值}"
spark = SparkSession.builder()
// 创建应用上下文信息
jsc = new JavaSparkContext(spark.sparkContext());
// 设置内存大小,值为spark.driver.memory + spark.executor.memory * {并发度}
config.setMemorySize()
// 初始化SparkOptimizer实例
optimizer = new SparkOptimizer(config, jsc);
// 初始化OptimizerToucher构建工厂方法
() -> new OptimizerToucher(config)
// 初始化SparkOptimizerExecutor构建工厂,i表示线程号
(i) -> new SparkOptimizerExecutor(jsc, config, i))
// 调用OptimizerToucher构建工厂创建OptimizerToucher实例
toucher = toucherFactory.get();
// 调用SparkOptimizerExecutor构建工厂创建OptimizerExecutor实例,数量为配置的并发度
executors = new OptimizerExecutor[config.getExecutionParallel()];
// 注册resource-id信息
toucher.withRegisterProperty(“resource-id”, config.getResourceId());
// 获取optimizer中的toucher属性,OptimizerToucher的主要作用是维护优化器与AMS(Amoro Management Service)之间的通信和状态同步
toucher = optimizer.getToucher()
// 注册job-id信息
toucher.withRegisterProperty(“job-id”, spark.sparkContext().applicationId());
// 启动优化器
optimizer.startOptimizing();
LOG.info("Starting optimizer with configuration:{}", config);
// 为每一个executor启动一个线程,线程号为“Optimizer-executor-{optimizerExecutor.getThreadId()}”
executors.forEach(optimizerExecutor -> new Thread(optimizerExecutor::start).start());这里根据设置的并发度,并发启动多个OptimizerExector线程。
spark优化器对应的OptimizerExecutor实现类为org.apache.amoro.optimizer.spark.SparkOptimizerExecutor。
SparkOptimizerExecutor启动任务
SparkOptimizerExecutor通过start方法来启动任务,start方法执行过程如下:
org.apache.amoro.optimizer.common.OptimizerExecutor#start
优化器处于启动状态,则进入以下循环
while (isStarted())
// 请求AMS,获取要执行的任务
OptimizingTask task = pollTask();
if task != null
// 请求AMS(thrift api——ackTask),检查task是否有效
acknowledged = client.ackTask(token, threadId, task.getTaskId());
优化器处于启动状态,则进入以下循环,直到拿到一个优化任务
while (isStarted())
// 请求AMS(thrift api——pollTask),从AMS拉取优化任务
task = callAuthenticatedAms((client, token) -> client.pollTask(token, threadId));
if (task != null)
// 如果task不为空,则退出当前循环
break
else
// 如果task为空,则等待5秒,然后进入下一次循环
waitAShortTime();
if acknowledged
// 执行优化任务
result = org.apache.amoro.optimizer.spark.SparkOptimizerExecutor#executeTask(task);
ImmutableList<OptimizingTask> of = ImmutableList.of(task);
jsc.setJobDescription(jobDescription(task));
SparkOptimizingTaskFunction taskFunction = new SparkOptimizingTaskFunction(getConfig(), threadId);
// 执行优化逻辑
List<OptimizingTaskResult> results = jsc.parallelize(of, 1).map(taskFunction).collect();
return results.get(0);
// 优化任务执行结束
completeTask(result);
// 请求AMS(thrift api——completeTask),告知当前任务已结束
client.completeTask(token, optimizingTaskResult);
进入下一个循环,如果循环中有一场,则直接输出日志,并不会退出循环
优化器不处于启动状态,则直接结束OptimizerExecutor#start函数和类调用过程如下图所示:
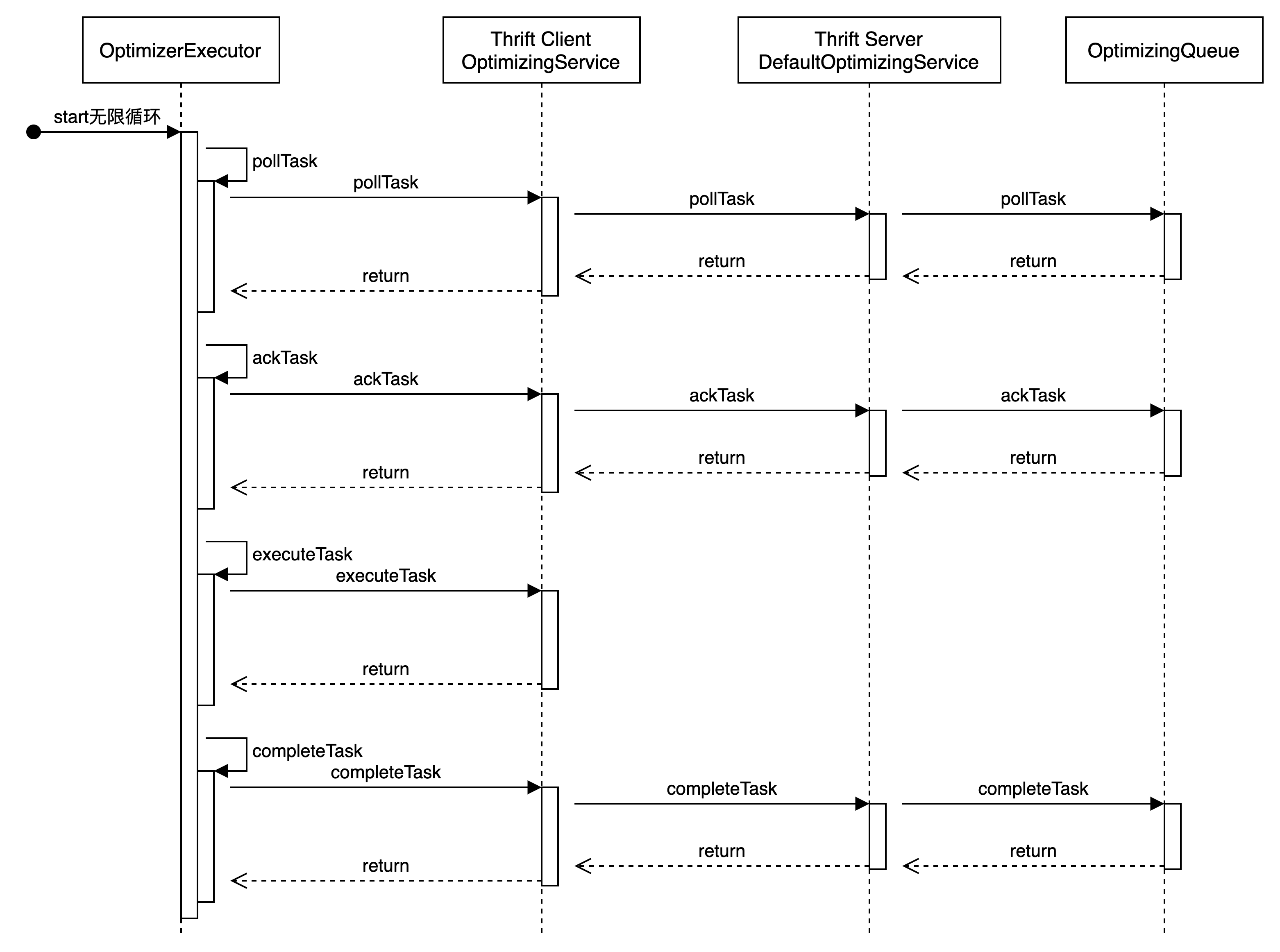
拉取任务信息
优化器执行的第一步是向AMS请求需要被优化的表信息。
OptimizerExecutor#pollTask最终需要请求到AMS的OptimizingQueue.pollTask方法,OptimizingQueue.pollTask的逻辑如下图所示:
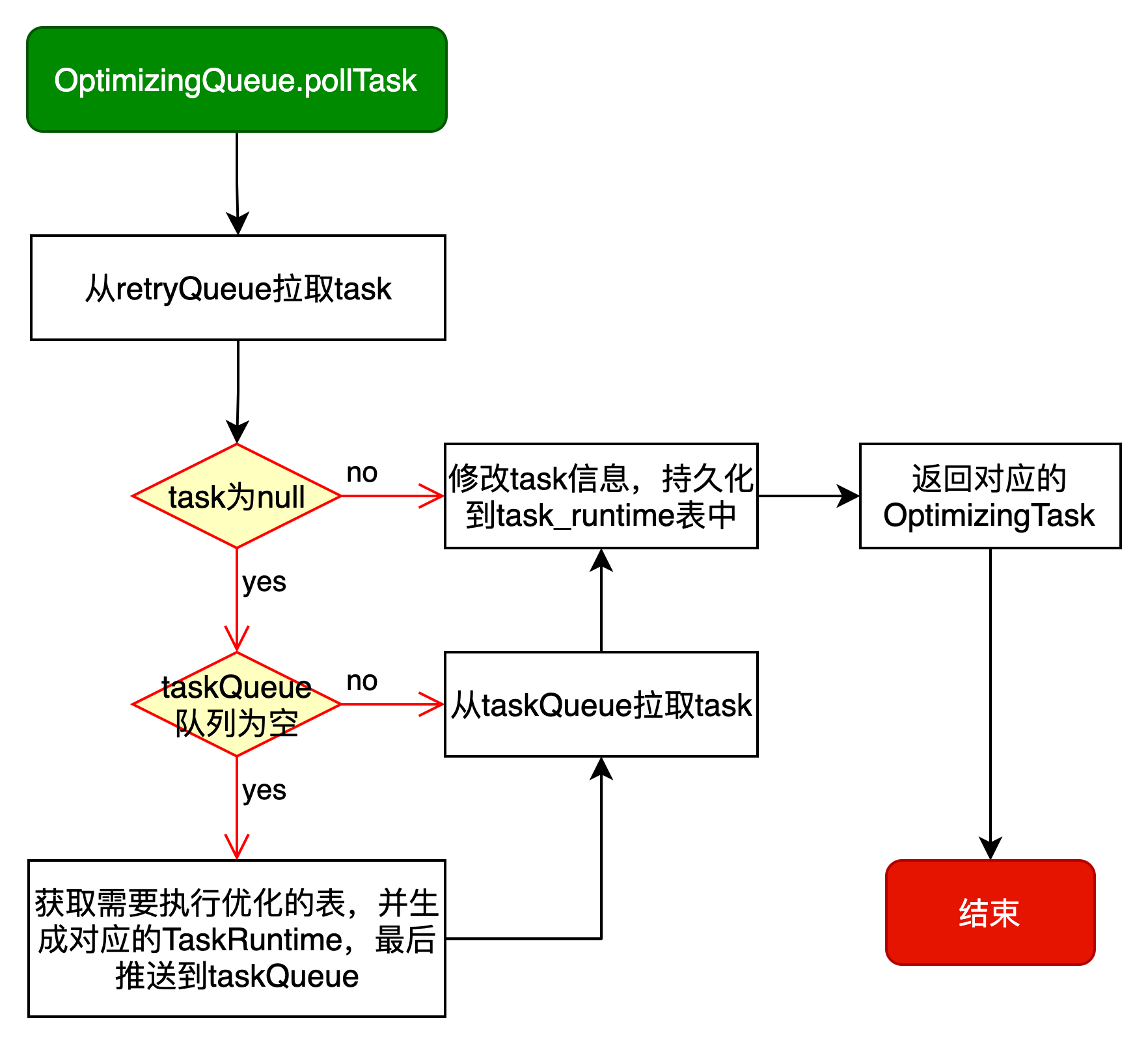
对应代码执行逻辑如下:
// 拉取任务
org.apache.amoro.server.DefaultOptimizingService#pollTask(authToken, threadId)
// 获取OptimizingQueue
OptimizingQueue queue = getQueueByToken(authToken);
// 从OptimizingQueue获取任务,超时时间由optimizer.polling-timeout配置,默认为3秒
task = queue.pollTask(pollingTimeout)
// 计算截止时间点:当前时间戳加pollingTimeout
long deadline = calculateDeadline(pollingTimeout);
TaskRuntime<?> taskRuntime = org.apache.amoro.server.optimizing.OptimizingQueue#fetchTask();
// 首先,从retryTaskQueue中提取
retryTaskQueue.poll();
// 如果retryTaskQueue中取不到,则从tableQueue中取
tableQueue.stream().findFirst()
// 如果taskRuntime为空,且未超过截止时间,则执行以下循环
while (taskRuntime == null && waitTask(deadline)) {
// 再次执行OptimizingQueue#fetchTask()方法
taskRuntime = org.apache.amoro.server.optimizing.OptimizingQueue#fetchTask();
}
return taskRuntime;
if task == null
// 没有从queue中获取到任务,即不存在需要被优化的表
return null
else
// 从queue中获取到需要执行的任务,则解析为OptimizingTask,并返回
return extractOptimizingTask(task, authToken, threadId, queue)task_runtime记录着任务执行记录,对应状态机如下图所示:
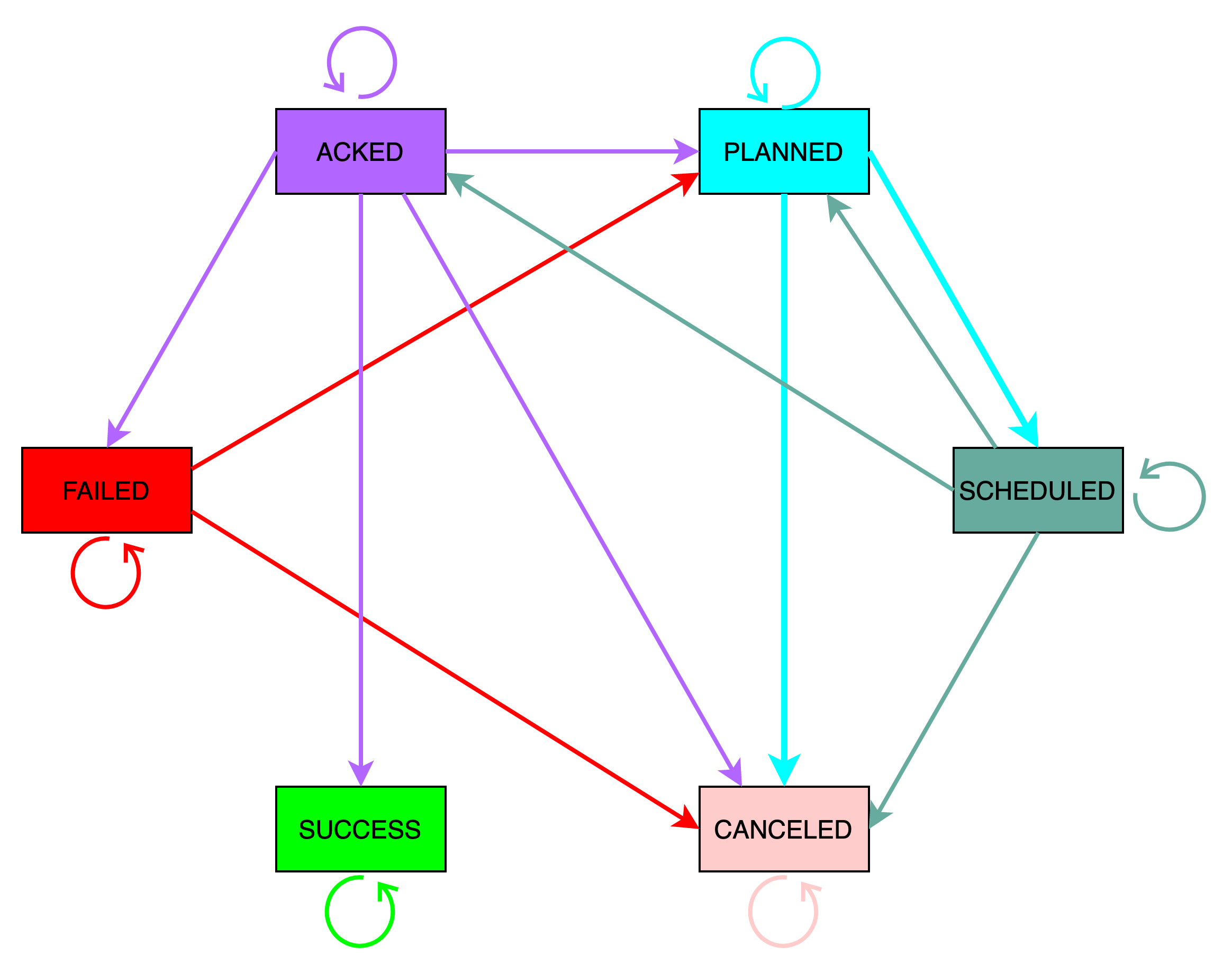
包含6个状态