Apache Iceberg不仅仅是一种新的表格式,更是一种革命性的架构范式,旨在将数据湖提升为具备数据库级别可靠性和智能的“数据湖仓”(Lakehouse)。Iceberg通过其独特的三层架构——数据层、元数据层和目录层——彻底解耦了逻辑表定义与物理文件布局,从而实现了ACID事务、乐观并发控制、灵活的Schema演进、隐藏分区以及强大的时间旅行能力。
下面我们开始了解iceberg中的一些核心概念和设计方法。
Iceberg Table Format Version
iceberg表格式版本,目前支持v1、v2、v3共三个版本,v4版本正处于开发状态,不同版本的表格式定义参考官网https://iceberg.apache.org/spec/
V1版本专注于解决大规模批处理分析的问题。
V2版本引入了行级删除,为事务性用例打开了大门。
V3版本中的特性——特别是删除向量和行级血缘——明确指向了对实时和流处理能力的战略性推动。
不同表格式实现原理
iceberg中定义了不同的类(V1Metadata、V2Metadata、V3Metadata),用于操作ManifestFile、DataFile、DeleteFile,以实现不同表格式版本的标准。
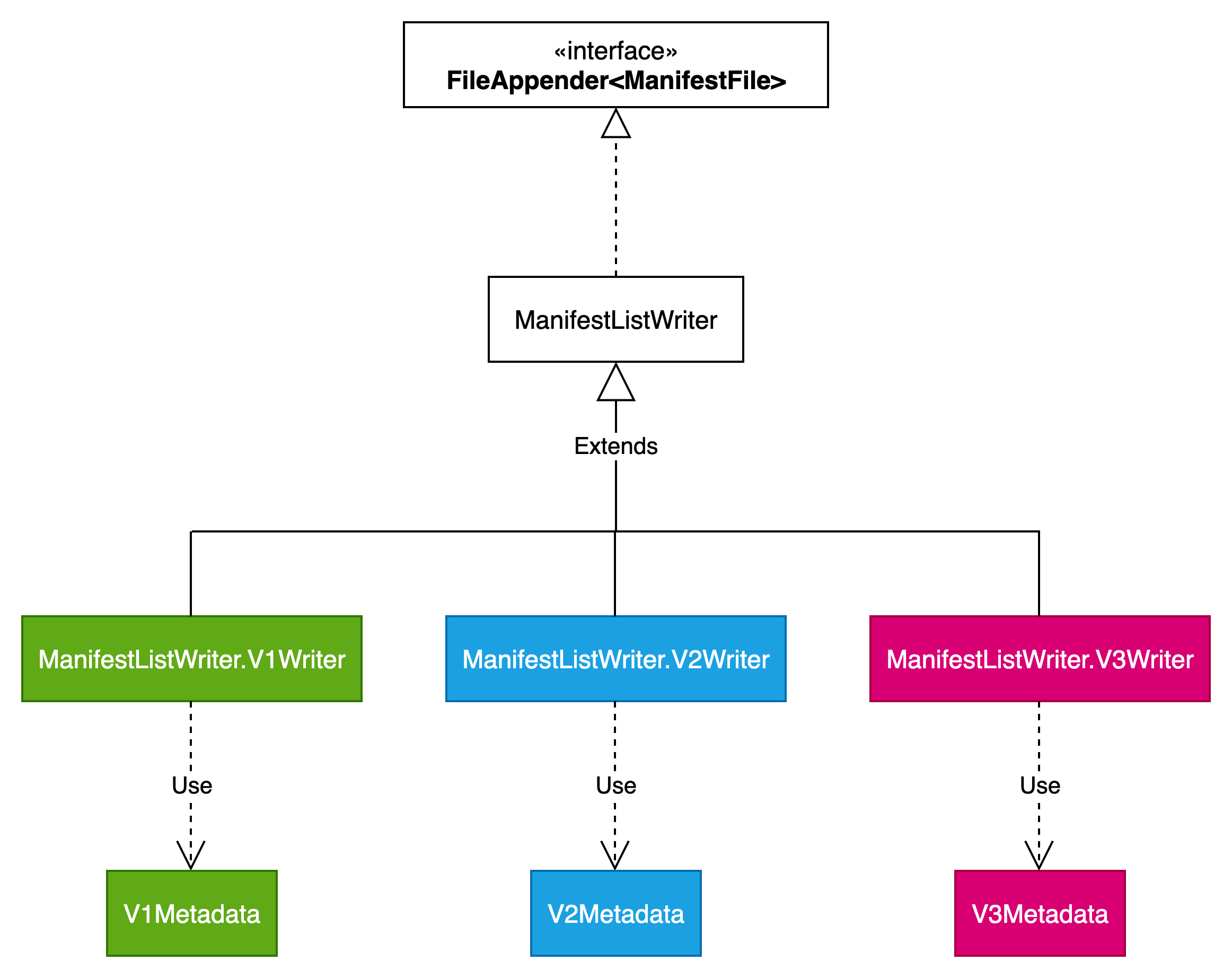
ManifestFile
ManifestFile写操作相关类结构如下图所示:
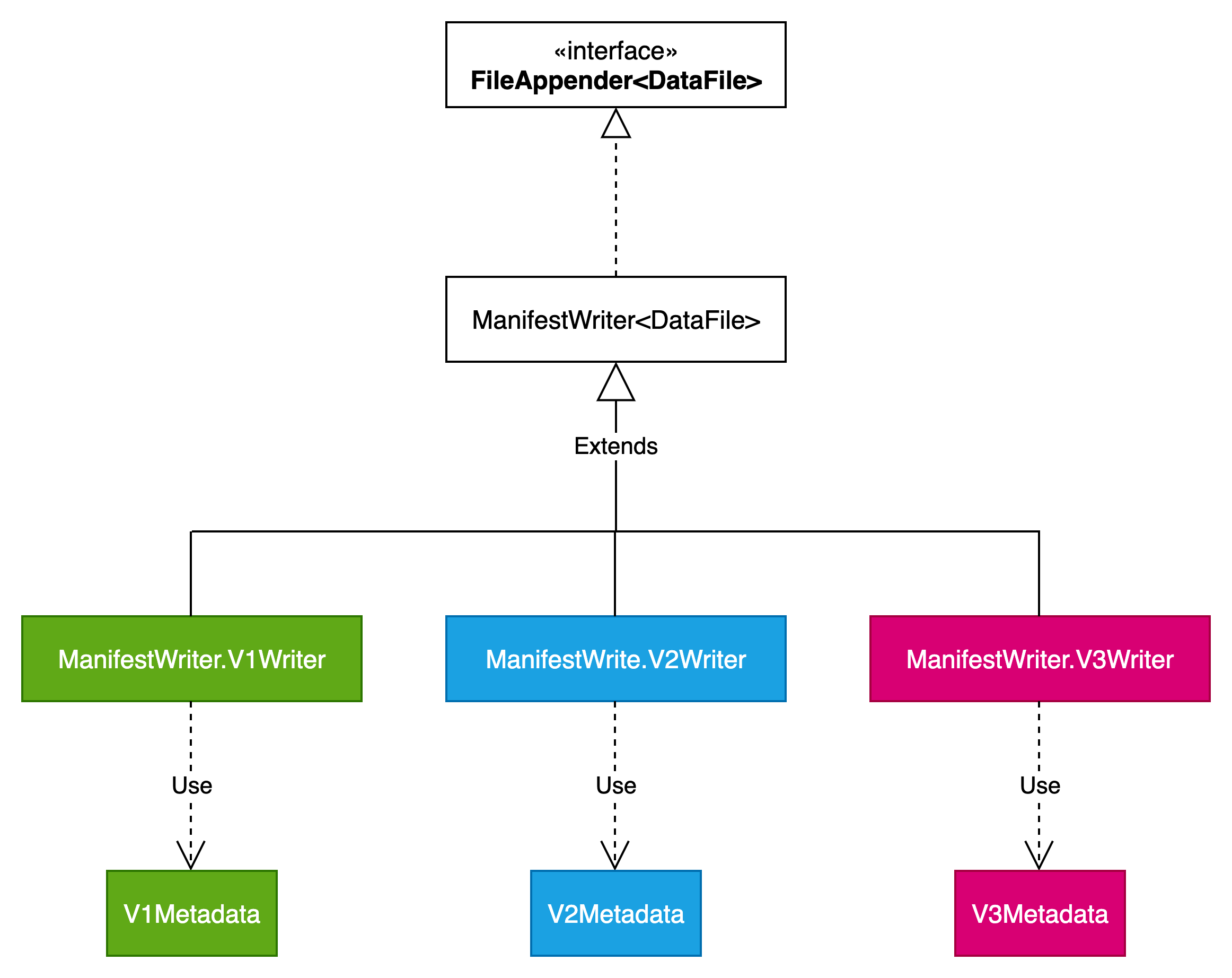
DataFile
DataFile写操作相关类结构如下图所示:
DeleteFile写操作
DeleteFile写操作相关类结构如下图所示:
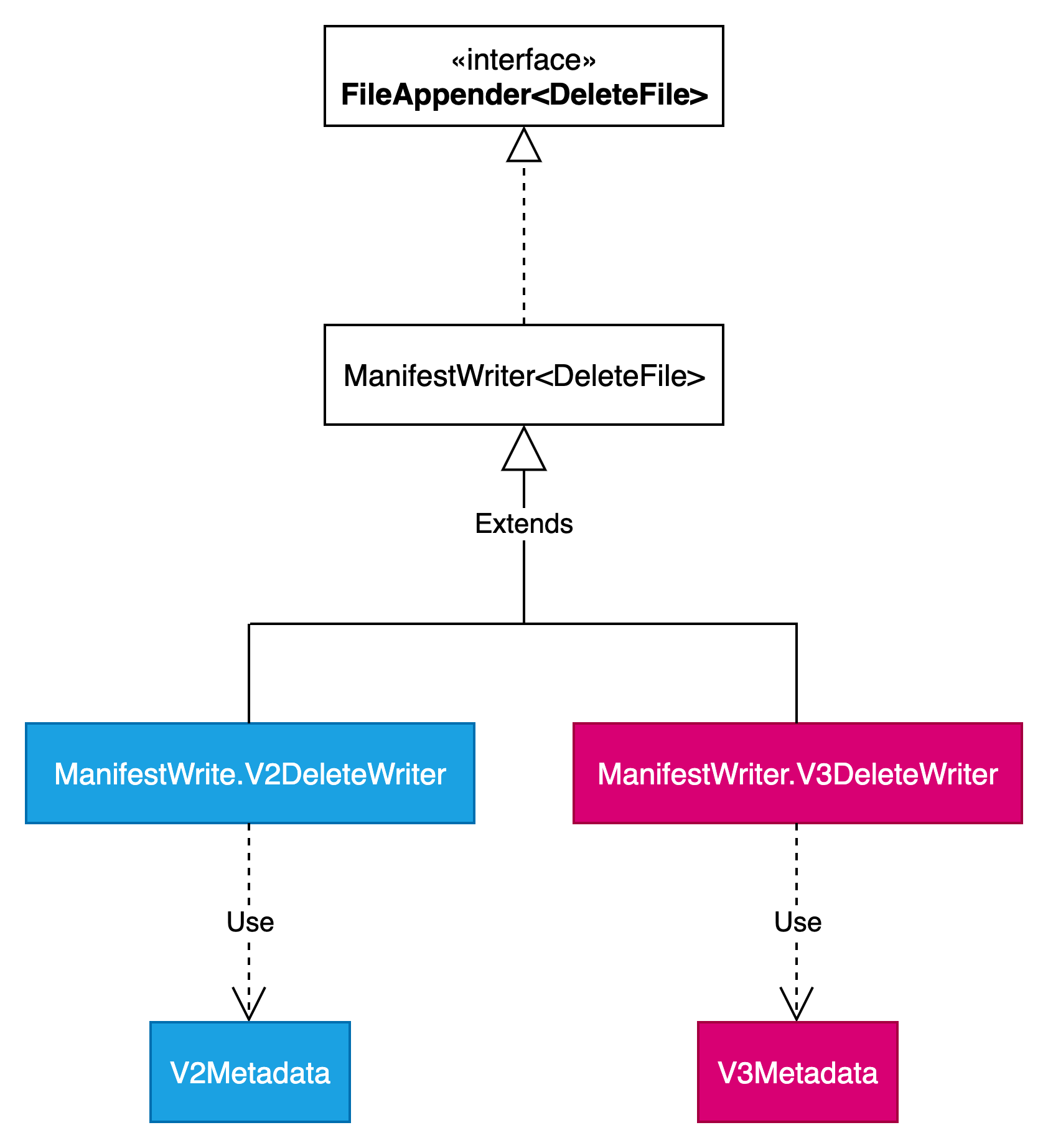
v1不支持行级别delete,所以没有对应的delete文件。
v1(Analytic Data Tables)
v1是最原始的iceberg表格式,主要用于离线分析场景。
v1适用场景
(1)离线分析场景
数据更新频率低,以全量扫描为主(如T+1报表)。
对查询性能要求较高,需快速读取压缩后的数据文件。
(2)计算引擎版本限制
无法升级至支持V2表的版本(如Spark 3.0以下)。
需确保与现有基础设施的兼容性。
(3)成本敏感型项目
对存储和计算资源高度敏感,需最小化元数据管理开销。
示例:冷数据存储、备份归档。
v2(Row-level Deletes)
iceberg-0.10.0版本开始支持v2格式,主要功能是“行级别删除”。
V1表通过Manifest文件和快照机制,为离线分析场景提供了稳定的数据版本管理能力。然而,其元数据膨胀、更新成本高等问题在V2表中得到了显著改善。
v2适用场景
v2表适合实时数据写入与更新、高级查询性能需求、基础设施升级场景等场景
(1)高更新频率场景
用户行为分析:需要实时记录用户点击、浏览等行为,并支持快速更新用户画像。
实时推荐系统:根据用户最新行为动态调整推荐结果,要求数据更新延迟低于1分钟。
(2)行级操作需求
数据修正与回滚:支持对单条记录进行更新或删除(如修正用户信息、回滚错误数据)。
事务性操作:确保多个行级操作的原子性,避免数据不一致问题。
(3)交互式分析与实时报表
动态分区裁剪:在查询时自动跳过无关分区,减少数据扫描量(如按时间、地域过滤)。
列剪裁与谓词下推:利用统计信息优化查询计划,仅读取必要列和满足条件的行。
(4)复杂查询优化
多表连接与聚合:通过元数据索引加速表连接和聚合操作(如Bloom过滤器快速定位匹配行)。
增量查询:基于时间戳或版本号查询最新数据变化(如WHERE hoodiecommit_time > '20231001')。
(5)计算引擎兼容性
Spark 3.0及以上:支持Iceberg V2表的行级更新、动态分区裁剪等特性。
Flink 1.13及以上:通过Flink Iceberg Sink实现端到端的流式写入与更新。
(6)存储与计算分离架构
云对象存储(如S3、OSS):利用Iceberg V2表的元数据分片与索引,减少对远程存储的频繁访问。
湖仓一体(Lambda架构):通过V2表统一批处理与流处理的数据存储,避免数据冗余。
v3(Extended Types and Capabilities)
iceberg-1.7.0版本开始支持v3格式,主要功能是面向实时处理。
Iceberg V3规范引入了强大的新功能,扩展了其应用场景
(1)删除向量 (Deletion Vectors):一种更高效的行级删除格式,显著提升了读时合并 (Merge-on-Read, MOR) 策略的性能。这减少了写放大,使Iceberg更适用于流式处理和高频更新的工作负载
(2)行级血缘 (Row Lineage):引入了系统列(_row_id, lastupdated_sequence_number),明确追踪行随时间的变化。这为变更数据捕获 (CDC) 工作流提供了内置支持,简化了下游复制和物化视图的维护
(3)扩展的数据类型:增加了对半结构化 (variant) 和地理空间 (geometry, geography) 数据的支持,使Iceberg成为一个更通用的格式,能适应更广泛的现代应用
v4
正处于开发状态,未被社区正式接受
Apache Iceberg V4 正在酝酿一项重要的元数据格式改进,其核心目标是解决当前版本在频繁数据更新时或者数据量比较小的表在写入时,所面临的元数据写入开销问题。 目前,Iceberg 创建一个新快照(snapshot)必须至少写入一个 manifest 文件和一个 manifest list 文件,这种“多文件写入”模式在高吞吐场景下成为性能瓶颈。为此,社区提出“单文件提交”的设计思路:计划重构 v4 的元数据结构,允许 manifest list 层直接存储数据文件和删除文件的引用信息。这意味着在大多数情况下,提交一次变更只需写入一个新的元数据文件,从而显著降低事务操作的成本和延迟。
该优化方案同时瞄准了多个关联问题: 首先,它致力于减少因海量细小 manifest 文件带来的问题——这些小文件不仅需要并行读取增加开销,后续还需进行 Compaction,新的元数据维护机制旨在从源头避免它们的产生。其次,方案计划增强 metadata skipping 能力,探索支持存储兼容地理空间数据等更复杂类型的聚合列统计信息,帮助查询引擎更精准地过滤无关数据分区。最后,针对删除操作,方案考虑引入软删除机制来避免重写整个现有 manifest 文件(类似 metadata deletion vector),进一步减少 I/O 消耗。
Iceberg Time Travel
iceberg支持时间旅行功能,具体说明参考官网https://iceberg.apache.org/spec/#point-in-time-reads-time-travel
在 Iceberg 中,每个表都由一系列的快照组成。每个快照都代表了表在某个时间点的状态。通过解析表的元数据文件,用户可以获取到当前表的快照 ID 以及所有的快照信息。这使得用户可以轻松地查询表的任意历史状态,实现时间旅行的效果。
时间旅行的原理
为了实现时间旅行,Iceberg 采用了以下技术:
快照 ID:每个快照都有一个唯一的 ID,用于标识该快照的时间点。用户可以通过快照 ID 来查询表在某个时间点的数据。
快照文件:每个快照都对应一个快照文件,该文件记录了该快照的所有数据文件信息。通过解析快照文件,用户可以获取到该快照的数据文件列表。
数据文件:数据文件是实际存储数据的文件。在 Iceberg 中,数据文件被分为多个分区,每个分区对应一个列。这使得 Iceberg 可以根据查询条件自动进行分区裁剪,提高查询性能。
实际上通过时间戳找到对应数据文件的原理与通过snapshot-id找到数据文件原理一样,在*.metadata.json文件中,除了有“current-snapshot-id”、“snapshots”属性外,还有“snapshot-log”属性。
我们可以看到其中有个 timestamp-ms 属性和 snapshot-id 属性,并且是按照 timestamp-ms 升序的。在 Iceberg 内部实现中,它会将 as-of-timestamp 指定的时间和 snapshot-log 数组里面每个元素的 timestamp-ms 进行比较,找出最后一个满足 timestamp-ms <= as-of-timestamp 对应的 snapshot-id,原理同上,通过snapshot-id再找到要读取的数据文件。
时间旅行的应用场景
时间旅行功能在数据湖架构中具有广泛的应用场景。以下是几个典型的应用示例:
数据回滚:当数据出现问题时,管理员可以通过时间旅行功能回滚到之前的快照,恢复数据到某个稳定的状态。
数据审计:审计人员可以通过时间旅行功能查询表的历史数据,验证数据的完整性和准确性。
数据对比:通过比较不同时间点的快照数据,用户可以发现数据的变化,从而分析数据的趋势和规律。
如何使用时间旅行
要使用 Iceberg 的时间旅行功能,用户需要按照以下步骤进行操作:
(1)创建 Iceberg 表:首先,用户需要在分布式存储系统上创建一个 Iceberg 表,并指定表的元数据和数据文件存储路径。
(2)写入数据:用户可以将数据写入 Iceberg 表中。在写入数据时,Iceberg 会自动生成快照文件和数据文件,并记录每个快照的快照 ID。
(3)查询历史数据:用户可以通过指定快照 ID 来查询表的历史数据。例如,用户可以使用类似以下的 SQL 查询语句来查询快照 ID 为 100 的数据:
SELECT * FROM my_table AS OF SNAPSHOT 100;读取某个时间戳之前的历史数据:
SELECT * FROM my_table TIMESTAMP AS OF '1996-10-26 01:21:00Z'(4)解析快照文件和数据文件:为了获取到表的历史数据,用户需要解析快照文件和数据文件。这可以通过编写自定义的代码或使用现有的工具来完成。
Iceberg Schema Evolution
iceberg schema evolution相关说明可参考官网https://iceberg.apache.org/spec/#schema-evolution
为什么需要Schema Evolution
用户的数据随着时间和业务量的增长会需要有一些格式上的变化,例如添加新的分区,更细的分区粒度等。
传统的Hive表如果想要处理这些变化可能需要创建一个新的表,将旧的数据读出来再写到新的表里。如果表的分区粒度也需要发生变化,例如,分区从天变成小时,那么还需要上层更改相关的查询语句,甚至还有引起正确性的问题。
所以表结构更新Schema Evolution是新一代数据湖的一个重要特性,使用新新一代数据湖的Schema Evolution特性很容易的对表的结构进行一些微调,例如添加某些列,从而满足用户数据变化的需求。
Iceberg支持的Schema Evolution功能
Apache Iceberg支持Full Schema Evolution的功能,包括类型晋升(比如number精度提高,无法精度降低,精度降低会有损数据准确性)、添加列、删除列、更新列、更新分区列等操作。用户可以任意的对表的结构进行原地更新,包括对普通列以及嵌套类型的列进行结构更新,甚至当用户的存储更换时还支持对分区的列进行更新。
Iceberg Schema Evolution如何实现
Iceberg的表结构更新是内在的元信息更新,不需要花费数据迁移或者数据重写的代价。
Iceberg Schema类结构
Iceberg Schema由org.apache.iceberg.Schema类定义,类结构如下图所示:
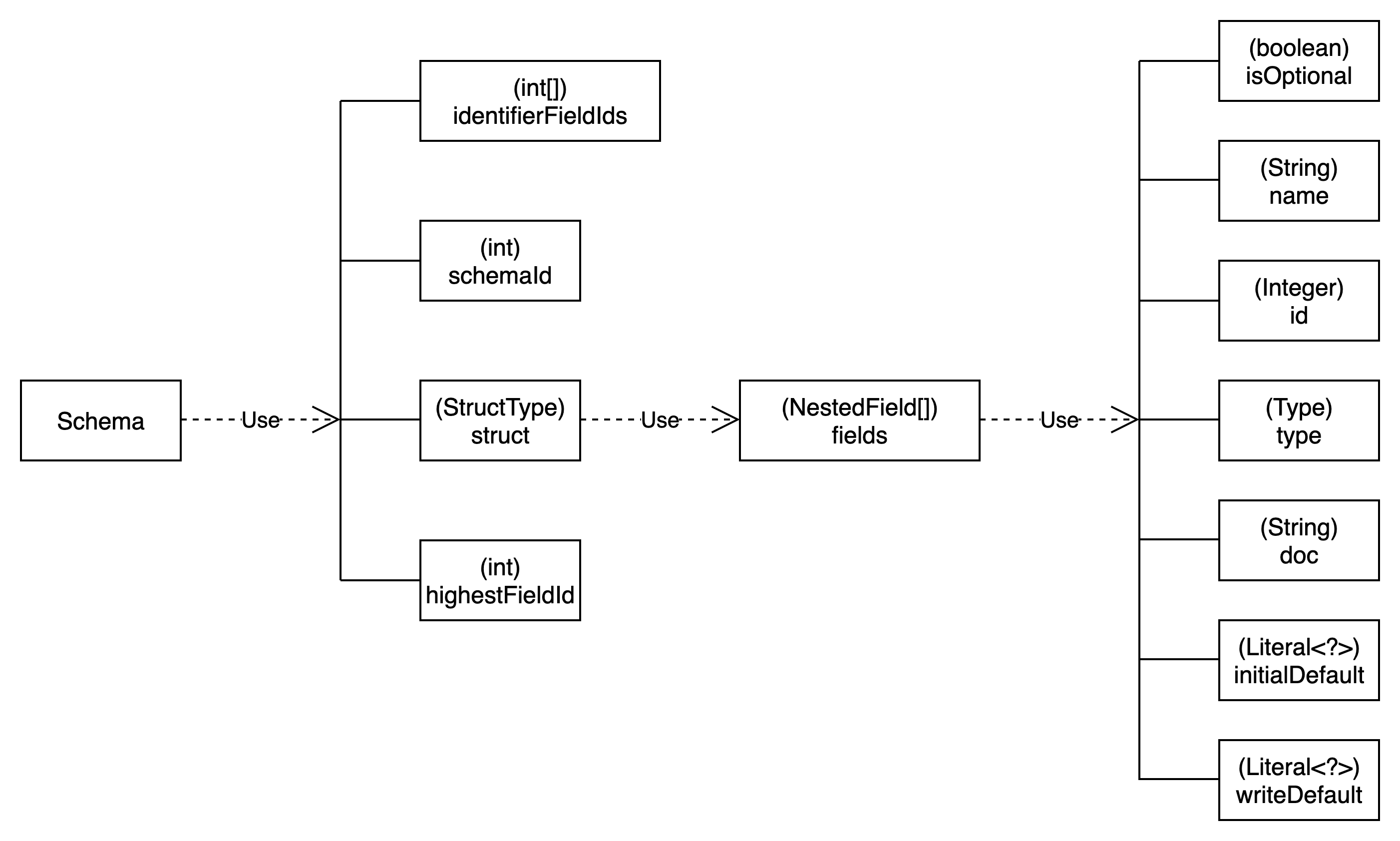
Iceberg Schema定义了schemaId和所有字段说明(NestedField)。
Iceberg Schema Visitor
Iceberg还定义了一系列的visitor用于访问和更新Schema。目前支持的schema visitor如下图所示:
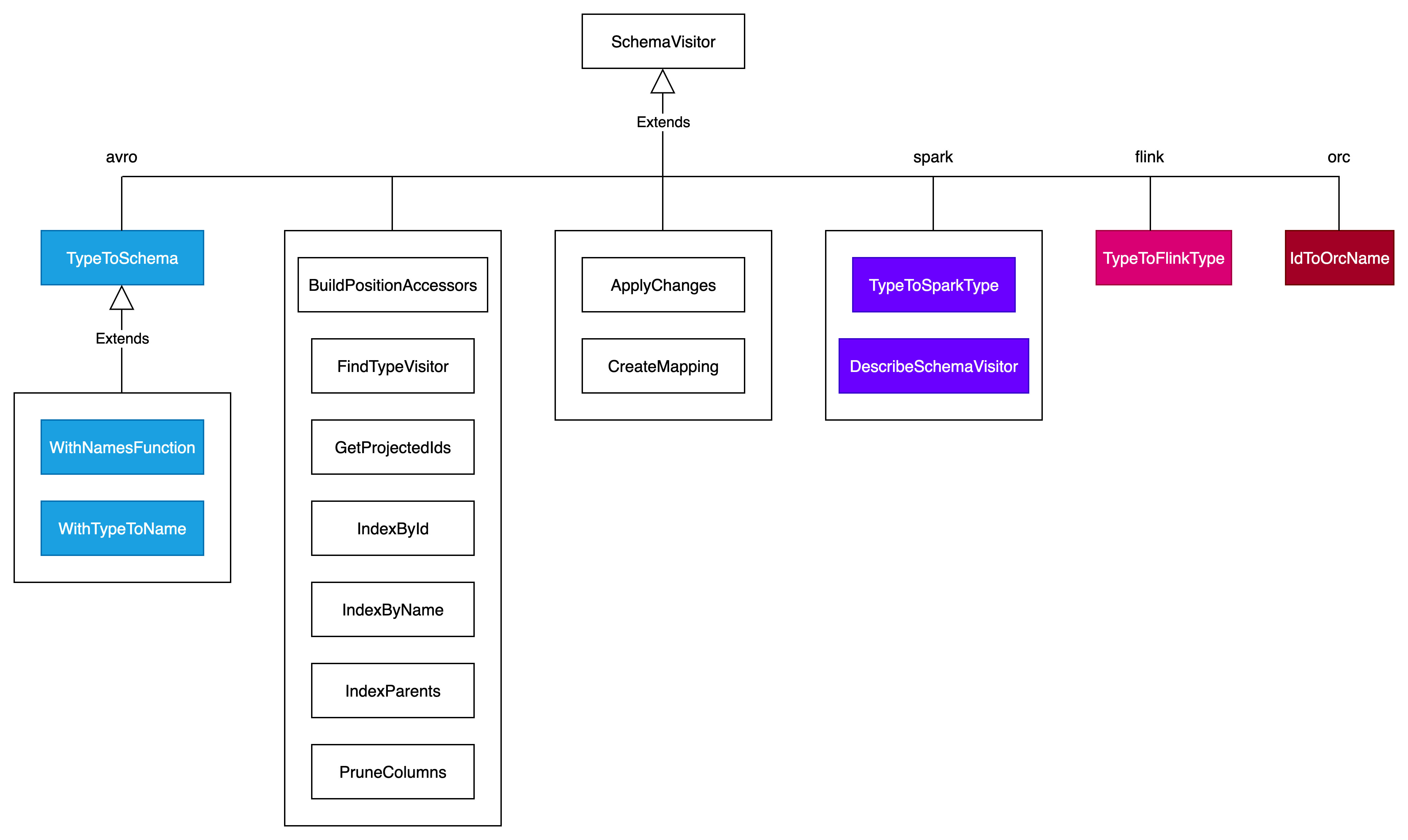
(1)与Spark Type转换的Visitor
两个Schema Visitor, TypeToSparkType 和SparkTypeToType, 这两个visitor可以对已有的表结构进行深度遍历,并在遍历同时生成另外一种格式的表结构。我们看下其中一个的具体visit方法
(2)与Flink Type转换的Visitor
一个Schema Visitor:TypeToFlinkType
(3)与Avro Schema互相转换的Visitor
两个Schema Visitor:TypeToSchema和SchemaToType
(4)更新Schema的Visitor
Schema更新由ApplyChanges这个Schema Visitor来完成,它包含了新增列,删除列,更新列三个操作
通过这套独立的Schema逻辑以及一系列visitor,Iceberg Schema可以不用和Spark 的Schema以及底层的文件格式Schema耦合,从而实现 full schema evolution。
Iceberg Partition Evolution
Partition Evolution也是Schema Evolution的一种。
除了支持Spark与Hive一样的显示分区,Iceberg还支持隐式分区,这种隐式分区的方式使得分区更加灵活,可以通过以某些列作为输入,然后指定一个变换函数结合起来作为一个分区格式。
Iceberg官方支持一些Transform转换函数,如果你觉得这些不够用,还可以自己实现一个Transform接口来指定分区策略。
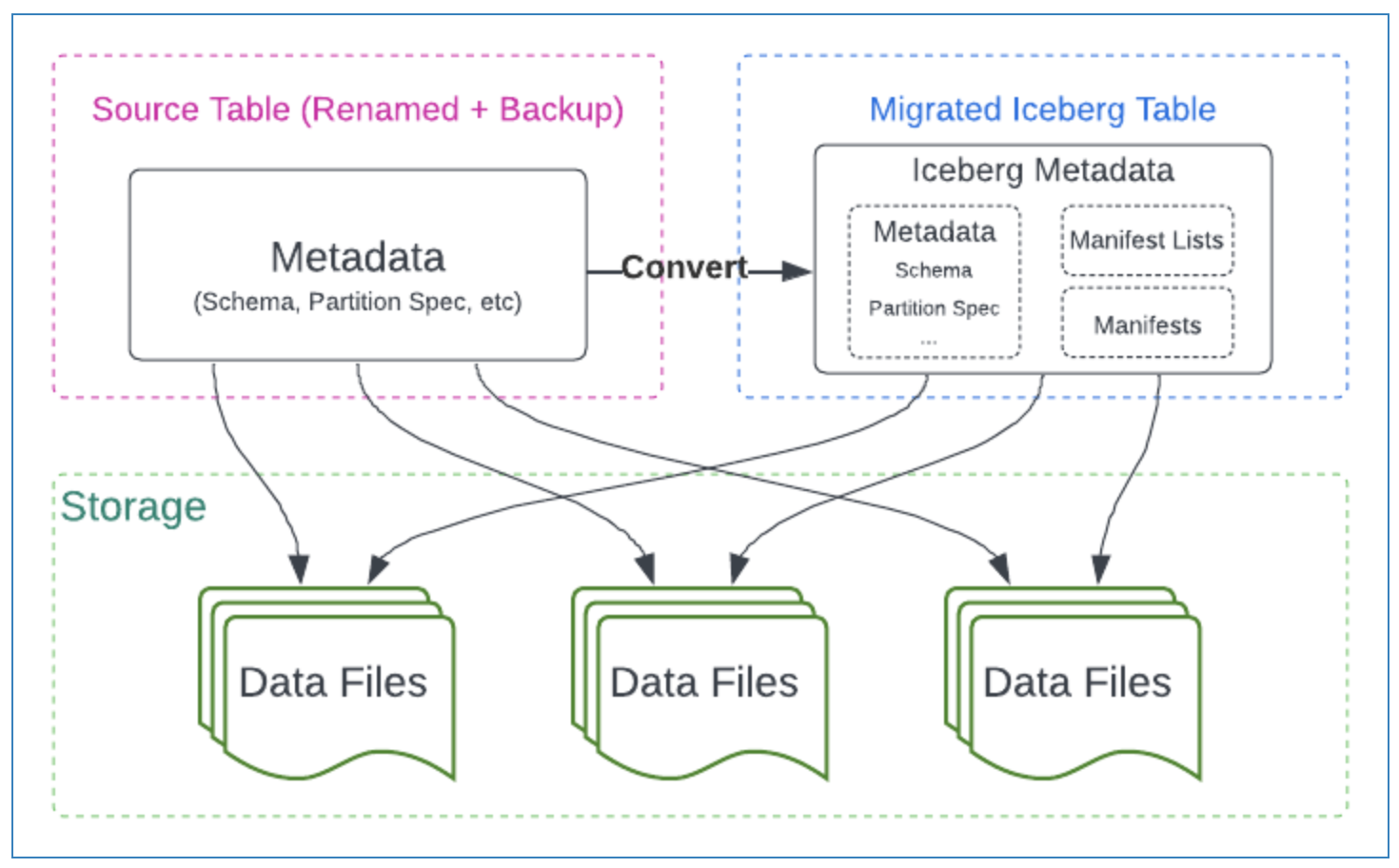
在隐式分区技术的基础上,Iceberg实现了Partition Evolution,这个功能可以让上层的查询语句不需要做任何的更新,仍然可以无缝的使用分区过滤功能。举例来说,原先你的数据是按照日期进行分区,随着数据不断增长原先分区里的数据越来越多,分区过滤后数据还是很多,现在想换下分区策略,改成小时分区。
iceberg partition变更的过程如下
Iceberg DeleteFile行级删除
iceberg v2支持对表数据的行级别删除,此功能是通过DeleteFile来实现的。
DeleteFile类结构
DeleteFile描述了在读取数据时那些需要被删除的行的数据集, 它可以使用基于位置的数据集(position-based delete file)来描述,也可以使用基于值数据集(value-based delete file)来描述,删除文件的格式和原数据文件的格式一致,可以同样进行信息统计实现过滤谓词下推。delete file 和data file 文件类型靠 content 字段区分。
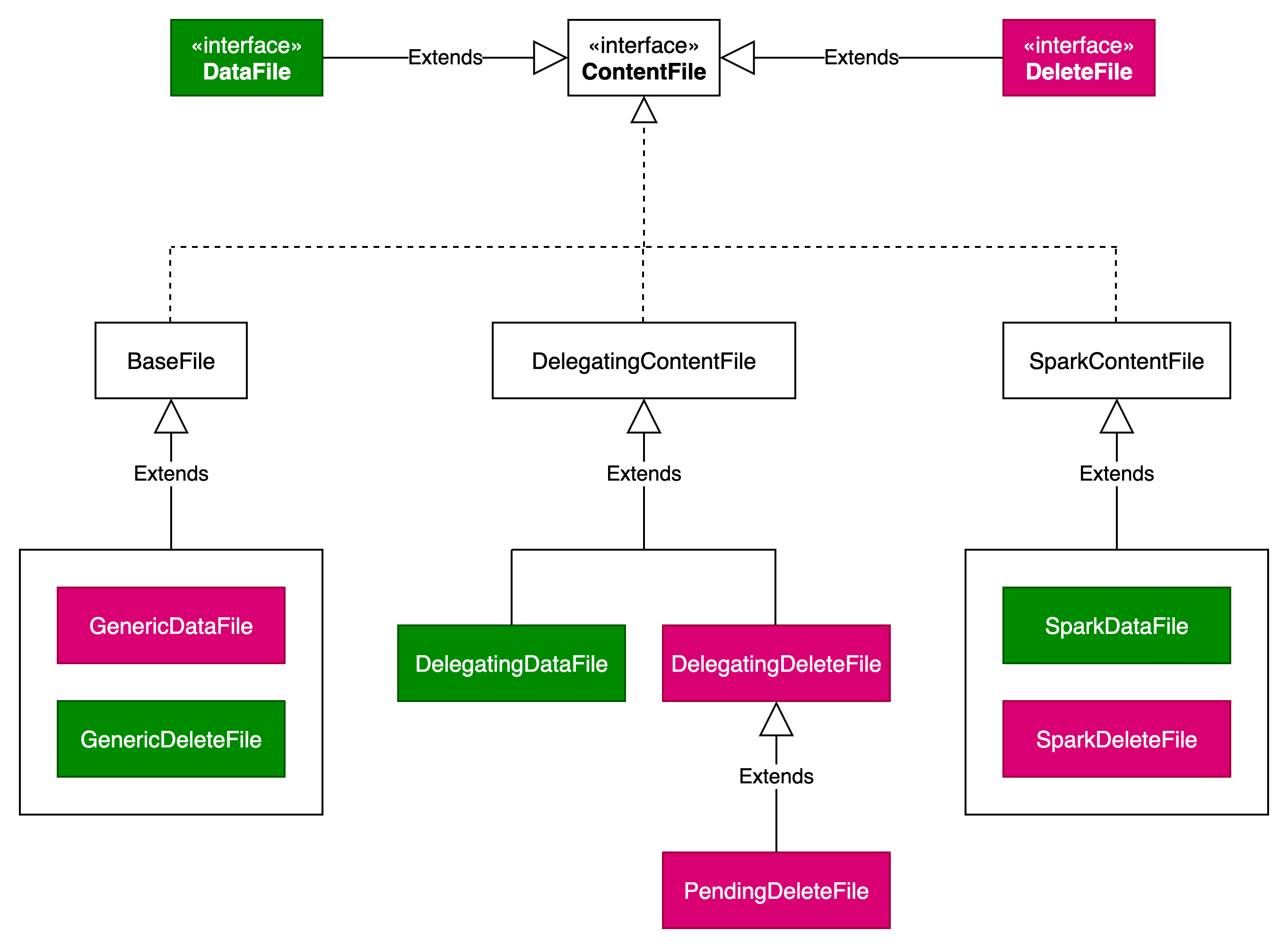
DataFile和DeleteFile都是继承自ContentFile接口。
DeleteFile生成过程
DeleteFile是在delete sql执行时生成的。
Iceberg的数据层包括:DataFile、DeleteFile和PuffinFiles。
Delete File又包括Positional Delete Files和Equality Delete Files。
Positional Delete Files
位置删除文件,它通过指定包含该行的特定文件的文件路径以及该文件中的行号来标明哪些行已被逻辑删除。
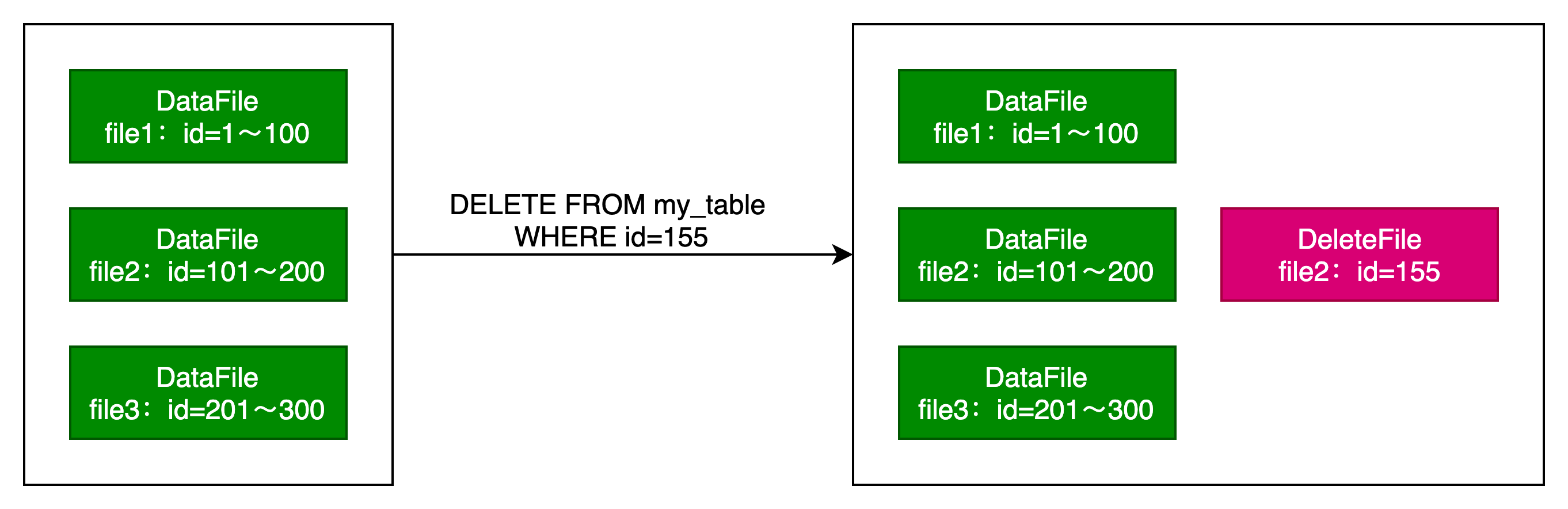
左边为原始的数据文件,在执行Delete删除语句后,在右边形成一个位置删除文件。DeleteFile中记录了行所在的DataFile(file2)和过滤条件(id=155)。
Equality Delete Files
相等删除文件,就是通过记录要删除的条件,在读取时通过匹配每一行来表示删除。方法是通过一个或多个字段的值来识别行,也可以通过此方法删除多行。
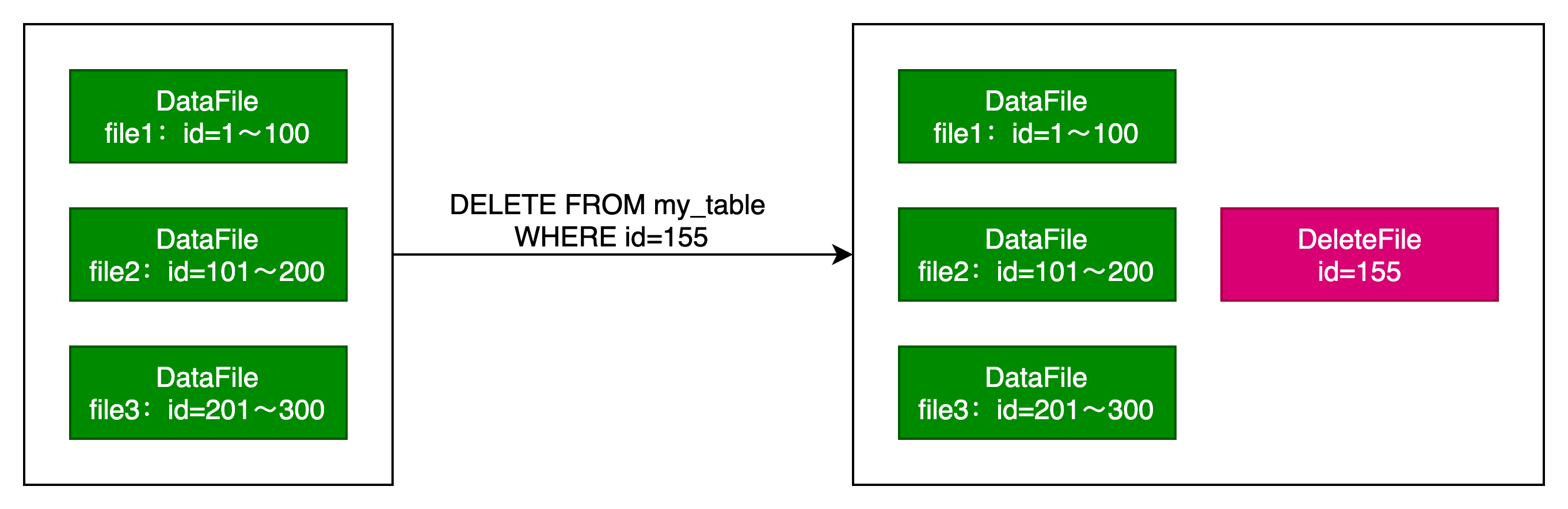
DeleteFile中只有过滤条件(id=155),没有记录行所在的DataFile,也就是针对所有DataFile进行过滤。
DeleteFile读取过程
当一个表有DeleteFile时,对这张表的查询会涉及到DeleteFile的读取。
描述一个Snapshot的基本元素如下所示:
class BaseSnapshot implements Snapshot {
private final long snapshotId;
private final Long parentId;
private final long sequenceNumber;
private final long timestampMillis;
private final String manifestListLocation;
private final String operation;
private final Map<String, String> summary;
private final Integer schemaId;
private final String[] v1ManifestLocations;
private final Long firstRowId;
private final Long addedRows;
}sequenceNumber表示序列号,描述Iceberg文件的顺序数,序列号越小,生成该文件的时间越早。它决定了DeleteFile是否应该和对应的DataFile进行合并,当删除文件的序列号大于数据文件的序列号时,需要进行数据合并。
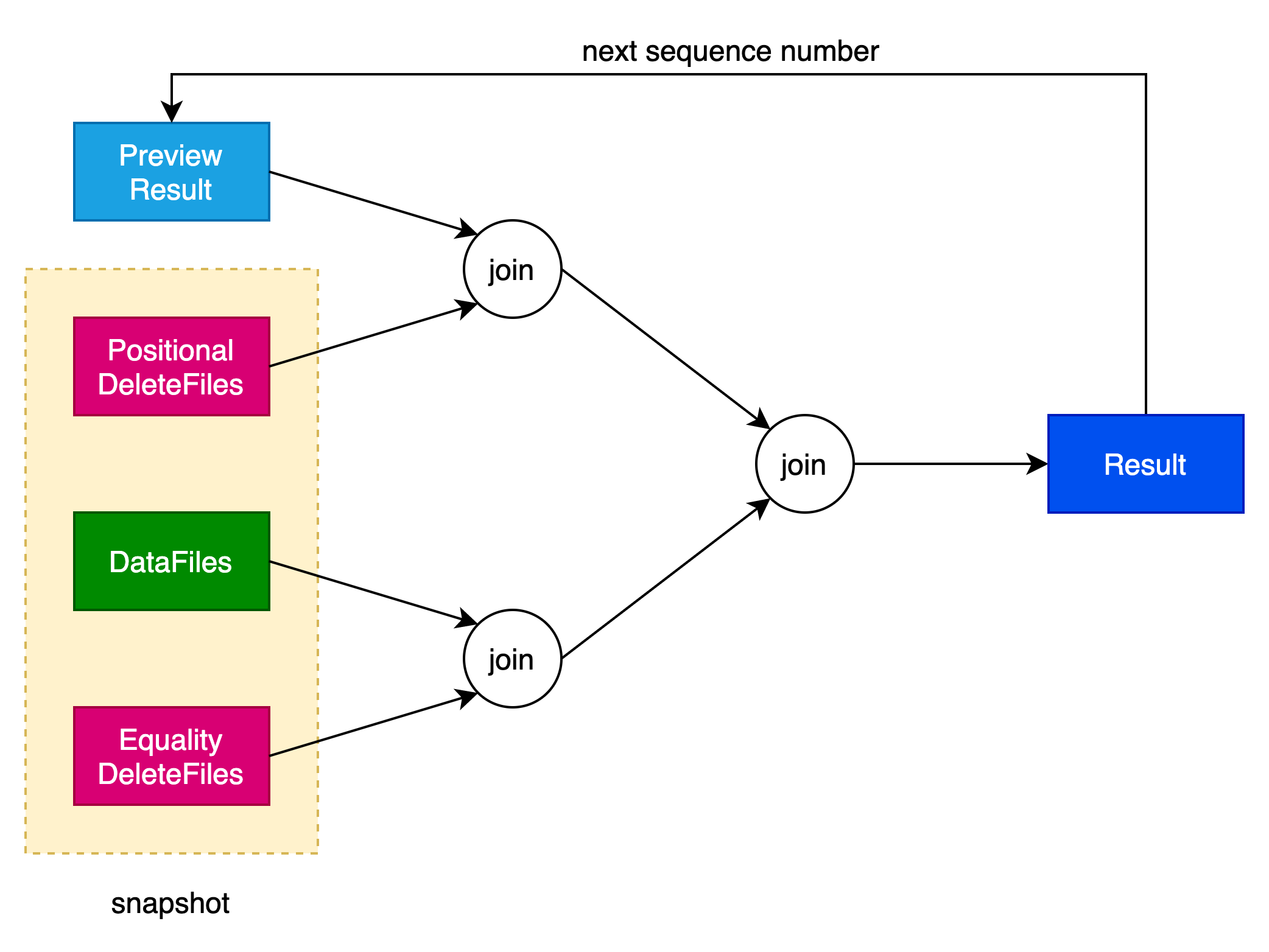
Review Result表示上一个snapshot的结果集。
Result表示sequence number对应的snapshot生成的结果集。
当sequence number比当前序列号小时,则继续进行下一个sequence number对应snapshot的合并操作。
合并过程分为以下步骤:
(1)选择data file文件中序列号最小(假设序列号为Seq0)的文件。 任何小于或等于 Seq0序列号 的delete file都可以丢弃。
(2)对于序列号等于 Seq0 的每个data file数据文件,过滤掉position delete file中提到的记录的所有行(不考虑序列号),并合并结果。
(3)对于每个具有数据或删除文件的后续序列号:
(3.1)将之前的结果与每个具有当前序列号的 equality delete file进行anti-join(对删除文件中的所有列使用等式连接)。
(3.2)使用position delete file(不考虑序列号)过滤所有具有当前序列号的数据文件。
(3.3)合并这两个步骤的结果。
基于Spark的Iceberg表管理
iceberg为spark引擎制定了一系列Procedure,用于在spark引擎管理iceberg表。
官方文档说明——https://iceberg.apache.org/docs/latest/spark-procedures/
Iceberg 中提供的所有Procedure都在system namespace 下,分快照管理、元数据管理、表迁移三种。如果需要使用Procedure则spark新增如下配置项
spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensionsProcedure类型
基本的Procedure工具类结构如下图所示:
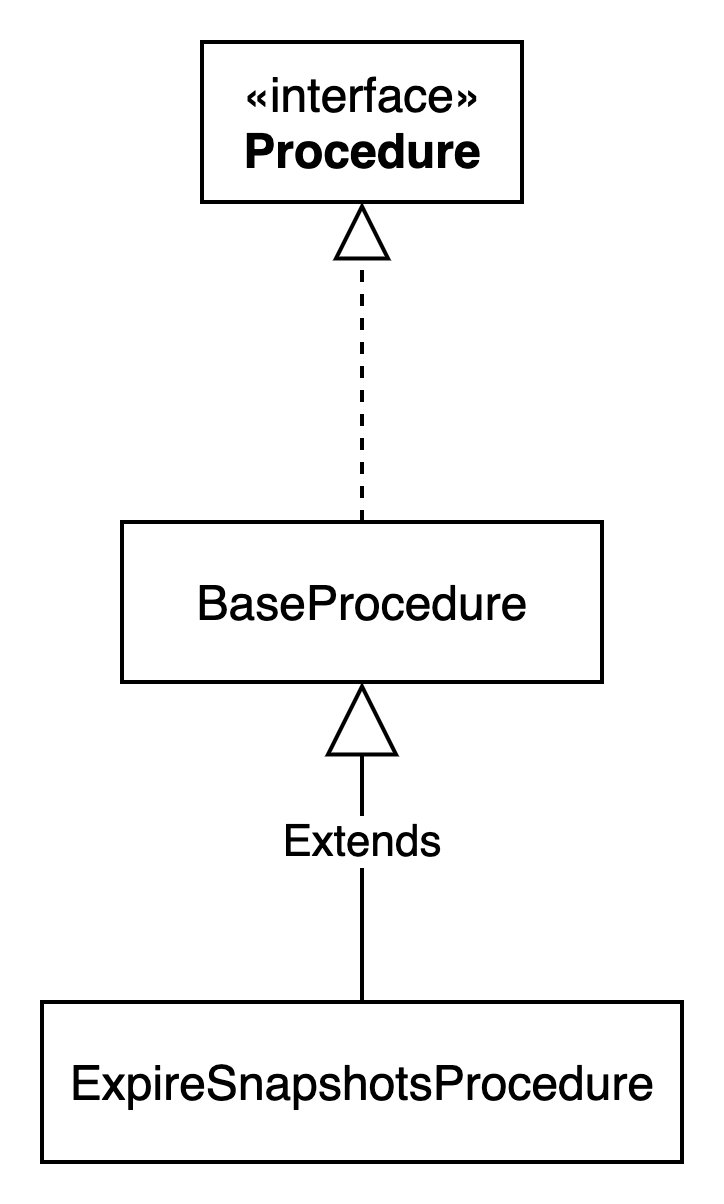
除了ExpireSnapshotsProcedure,iceberg还提供了18种不同的Procedure,这些Procedure在org.apache.iceberg.spark.procedures.SparkProcedures类中引用,并与对应的spark系统调用进行映射。
Iceberg快照管理
以下是快照管理相关的Procedure
(1)RollbackToSnapshotProcedure
回滚表到特定的快照ID,通过rollback_to_snapshot命令调用,入参有两个:
table(必须):string,表名
snapshot_id(必须):long,快照 ID
(2)RollbackToTimestampProcedure
回滚表到特定时间,通过rollback_to_timestamp命令调用,入参有两个:
table(必须):string,表名
timestamp(必须):long,回滚的时间戳
(3)SetCurrentSnapshotProcedure
设置表的当前快照ID,通过set_current_snapshot命令调用,入参有两个:
table(必须):string,表名
snapshot_id(必须):long,快照 ID
(4)CherrypickSnapshotProcedure
从现有快照创建新快照,通过cherrypick_snapshot命令调用,入参有两个:
table(必须):string,表名
snapshot_id(必须):long,快照 ID
Iceberg元数据管理
以下是元数据管理相关的Procedure
(1)ExpireSnapshotsProcedure
删除过期快照和相关数据文件,通过expire_snapshots命令调用,入参有四个:
table(必须):string,表名
older_than:timestamp,该时间戳之前的快照将被删除,默认为 5 天前
retain_last:int,和 older_than 同时存在的时候,要保留的快照数(默认为 1)
max_concurrent_deletes:int,用于删除文件操作的线程池大小(默认不使用线程池)
(2)RemoveOrphanFilesProcedure
删除Iceberg元数据中未被引用的文件,通过remove_orphan_files命令调用,入参有五个:
table(必须):string,表名。
older_than:timestamp,删除在此时间戳之前创建的孤立文件(默认为 3 天前)。
location:string,查找文件的目录(默认为表的位置)。
dry_run:boolean,当为 true 时,实际上不删除文件(默认为 false)。
max_concurrent_deletes:int,用于删除文件操作的线程池大小(默认不使用线程池)。
(3)RewriteDataFilesProcedure
合并小文件,加速文件扫描速度,通过rewrite_data_files命令调用,入参有五个:
table(必须):string,表名。
strategy:string,合并策略binpack或sort。默认为binpack。
sort_order:string,用以描述排序方式,多个字段之间用逗号分隔。如:name asc nulls last, age desc nulls first。
options:map<string, string>,用以重写文件时的其它参数。
where:string,指定过滤条件。
(4)RewriteManifestsProcedure
重写manifest文件,优化扫描计划,通过rewrite_manifests命令调用,入参有两个:
table(必须):string,表名。
use_caching:boolean,是否使用 Spark 缓存(默认为 true)。
(5)AncestorsOfProcedure
获取指定快照血缘关系,通过ancestors_of命令调用,入参有两个:
table(必须):string,表名。
snapshot_id(非必须):long,指定的快照 ID。
Iceberg表迁移
以下是表迁移相关的Procedure
(1)SnapshotTableProcedure
做iceberg表快照,在不影响原始表的情况下创建一个新的轻量级快照表用以测试,测试结束之后可以通过drop table删除掉。如果在新的快照表中没有插入新数据,则依然使用的是原始表的数据文件,如果插入操作,则新的数据文件放在快照表的数据目录下,不会影响原始表。
在新表中任何只影响元数据的操作都是允许的,如 inset、delete。但是会影响到物理数据文件的操作是禁止的,如删除过期快照(expire_snapshots),因为会影响到原始表。
通过snapshot命令调用,入参有四个:
source_table(必须):string,原始表表名。
table:string(必须):新表(快照表)表名。
location:string,新表的存储目录,默认有 catalog 管理。
properties:map<string, string>,添加到新表中的属性。
(2)MigrateTableProcedure
将一个非 Iceberg 表转为 Iceberg 表,原始表中的文件会加载到新的 Iceberg 表中,原始表中的 schema 信息、partition 信息、属性信息以及位置都会拷贝至新表。
通过migrate命令调用,入参有两个:
table(必须):string,需要迁移的原始表。
properties:map<string, string>,新 Iceberg 表的属性。
(3)AddFilesProcedure
将 Hive 或其它基于文件的表中的数据文件添加到指定的 Iceberg 表中,可以从一个或多个分区导入文件。add_files只会为需要导入的数据文件增加元数据信息,并不会物理地移动数据文件,而且不会考虑导入文件的 Scheme 信息是否和 Iceberg 表匹配。
通过add_files命令调用,入参有三个:
table(必须):string,目标表,数据被导入其中。
source_table(必须):string,源表,提供需要被导入的数据。如果是 Hive 或 Spark 中的表,可以为db.tbname;如果文件,可以为file_format.path。
partition_filter:map<string, string>,要从中导入的源表中的分区集合。
其他Procedure
以下是其他的Procedure
(1)ComputeTableStatsProcedure
通过compute_table_stats命令调用
(2)CreateChangelogViewProcedure
通过create_changelog_view命令调用
(3)FastForwardBranchProcedure
通过fast_forward命令调用
(4)PublishChangesProcedure
通过publish_changes命令调用
(5)RegisterTableProcedure
通过register_table命令调用
(6)RewritePositionDeleteFilesProcedure
通过rewrite_position_delete_files命令调用
(7)RewriteTablePathProcedure
通过rewrite_table_path命令调用
Procedure调用方式
可以在spark-sql命令行终端直接输入call命令,比如以下是调用expore_snapshots Procedure。
-- 基于参数位置
call catalog_name.system.procedure_name(arg_1, arg_2, ... arg_n);
-- 基于参数名称
call catalog_name.system.procedure_name(arg_name_2 => arg_2, arg_name_1 => arg_1);