1.问题描述
在kafka0.10版本的环境中,我们通过kafka-consumer-groups.sh --new-consumer模式describe一个group信息,发现有些消费分区对应的current-offset为unknown。
部分分区offset为unknown有一种场景是正常的,那就是这个分区长时间没有消息生产,导致消费组offset的信息超过offsets.retention.minutes(默认是1440分钟,即1天)未被更新,那么对应的offset信息会被清理,这是kafka自我保护的机制,防止消息堆积过多导致服务异常。
2.kafka-consumer-groups.sh源码解析
describe过程如下所示:
kafka-consumer-groups.sh --describe
kafka.admin.ConsumerGroupCommand
consumerGroupService赋值
如果命令行中有--new-consumer,则初始化KafkaConsumerGroupService(opts)
如果命令行中没有--new-consumer,则初始化ZkConsumerGroupService(opts)
consumerGroupService.describe
consumerGroupService.describeGroup
ZkConsumerGroupService#describeGroup
kafka.utils.ZkUtils#getTopicsByConsumerGroup
读取zookeeper上/consumers节点的信息
KafkaConsumerGroupService#describeGroup
kafka.admin.AdminClient#describeConsumerGroup
kafka.admin.AdminClient#describeGroup
coordinator = findCoordinator(groupId)
向coordinator发送DescribeGroups请求DescribeGroupsRequest
将请求结果封装成GroupSummary类型返回DescribeGroups请求处理过程如下所示:
# coordinator接收到DescribeGroups请求
kafka.server.KafkaApis#handle(DescribeGroupsRequest)
kafka.server.KafkaApis#handleDescribeGroupRequest
kafka.coordinator.GroupCoordinator#handleDescribeGroup
kafka.coordinator.GroupMetadataManager#getGroup
groupsCache.get(groupId)这里group信息完全从缓存中获取,而缓存groupCache在以下场景中会变化:
groupsCache的变化
kafka.coordinator.GroupCoordinator#handleLeaveGroup
group = groupManager.getGroup(groupId)
member = group.get(consumerId)
kafka.coordinator.GroupCoordinator#removeHeartbeatForLeavingMember(group, member)
移除consumer的心跳
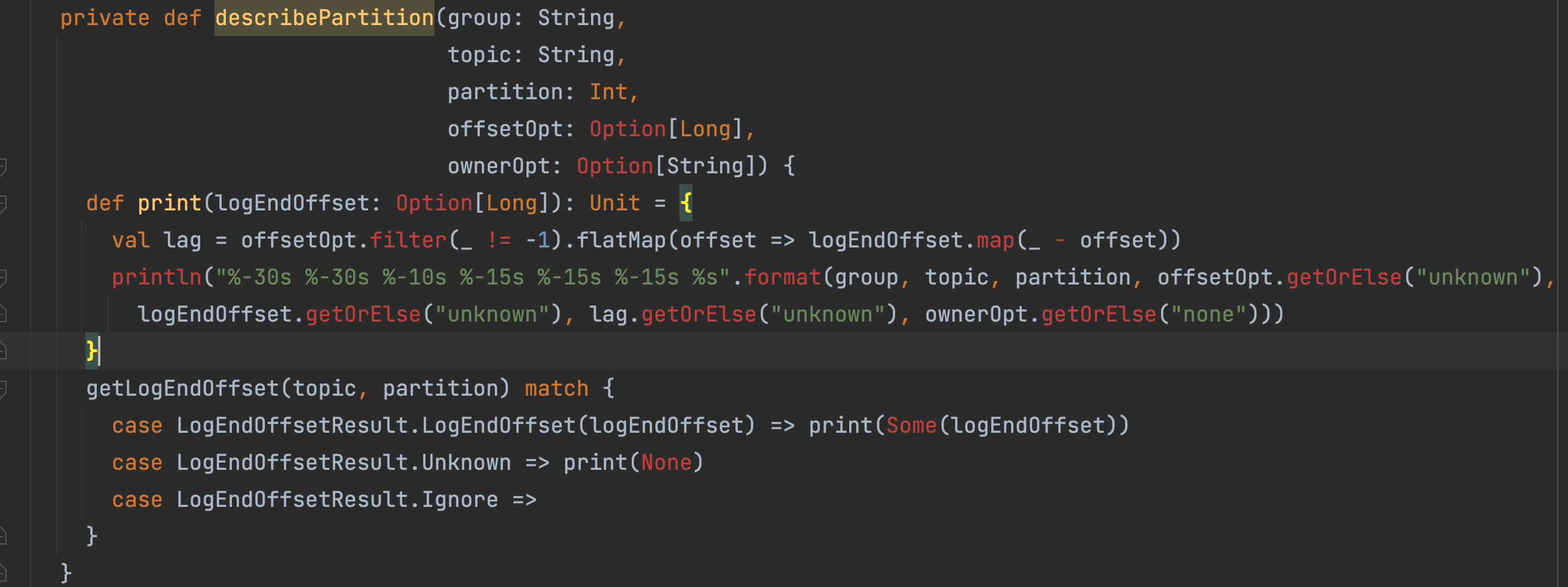
kafka.coordinator.GroupCoordinator#onMemberFailure(group, member)如果拿到的group信息中,没有某个分区的offset提交信息,则展示为unknown,如下图所示: