MySQL Innodb存储引擎支持扁平事务、带有保存点的事务、链事务、分布式事务。Innodb原生不支持嵌套事务。
1.Innodb事务实现
事务隔离性由锁来实现。
原子性、持久性由数据库的redo log来实现。
一致性由undo log来实现。
2.锁
锁机制用于实现共享资源的并发访问。
2.1.锁的分类
数据库中,lock和latch都是锁,但意义完全不同。
2.1.1.latch
称为闩锁,是轻量级锁,要求锁定时间非常短。如果时间长,则应用的性能会非常差。
Innodb存储引擎中,latch又分为了mutex(互斥量)和rwlock(读写锁)。
目的是用来表示并发线程操作临界资源的正确性,没有死锁检测机制。
通过以下命令可查看innodb中latch的情况
show engine innodb mutex;2.1.2.lock
lock的对象是事务,用于锁定数据库中的对象,比如表、页、行。一般lock的对象仅在事务commit或rollback后进行释放。
lock死锁检测和处理机制。
通过以下命令可查看innodb中lock的情况
show engine innodb status;
select * from information_schema.innodb_trx;
select * from information_schema.innodb_locks;
select * from information_schema.innodb_lock_waits;innodb中有以下四种lock的类型。
2.1.2.1.共享锁(S Lock)
允许事务读一行数据。
2.1.2.2.排他锁(X Lock)
允许事务删除或更新一行数据。
2.1.2.3.意向共享锁(IS Lock)
事务想要获得一张表中某几行的共享锁。
innodb支持多粒度锁定,允许事务在行级别和表级别的锁同时存在。
2.1.2.4.意向排他锁(IX Lock)
事务想要获得一张表中某几行的排他锁。
如果将上锁对象看成是一棵树,要叶子结点对象上X锁,则上层对象需要上IX锁。
意向锁不会阻塞除全表扫描以外的任何请求。
各种锁的兼容性如下表所示:
表示1个对象是否可以同时加上这两种锁,兼容表示可以,不兼容表示不可以。
2.1.3.latch vs lock
对比如下表所示:
2.2.一致性非锁定读
consistent nolocking read
innodb通过行多版本控制来读取当前执行时间数据库表中的行数据。如果读取的行正在执行DELETE或UPDATE操作,这时读取操作不会被阻塞,而是读取行的一个快照数据。
一个行记录可能有不止一个快照数据,一般称这种技术为行多版本技术,由此带来的并发控制,称之为多版本并发控制(Multi Version Concurrency Control,MVCC)。
2.3.一致性锁定读
某些情况下,用户需要显示地对数据库读取操作进行加锁以保证数据逻辑的一致性。
Innodb对于Select语句支持两种一致性的锁定读:
(1)select……for update:对读取的行加X锁。
(2)select……lock in share mode:对读取的行加S锁。
一致性锁定读必须在一个事务中,当一个事务commit后,锁就释放了。
2.4.行锁的算法
行锁的算法有三种
2.4.1.Record lock
单个行记录上的锁
2.4.2.Gap lock
间隙锁,锁定一个范围,但不包含记录本身。
2.4.3.Next-Key lock
锁定一个范围,并锁定记录本身。可以看成是Record lock + Gap lock。
此锁设计是为了解决幻读的问题。
2.4.锁如何实现隔离性
Read Committed和Repeatable Read隔离级别下,innodb存储引擎使用非锁定的一致性读。
Read Committed隔离级别下,一致性非锁定读取的是最新的一份快照数据。
Repeatable Read隔离级别下,一致性非锁定读取的是事务开始时的快照数据。
通过以下命令查看默认的事务隔离级别
select @@tx_isolation;3.redo log
redo log可以保证事务的原子性和持久性。
3.1.redo log结构
redo log基本上是顺序写的,数据库运行时不需要对redo log文件进行读取操作。
redo log记录的是物理操作日志,每个事务可能对应多个日志条目,事务的redo log是并发写入的,并非是在事务提交时写入。
redo log是以512字节进行存储的,也就是说redo log buffer、redo log file都是以block的方式进行保存的,也称为redo log block。
由于redo log block的大小和磁盘扇区的大小是一样的,都是512字节,因此redo log的写入可以保证原子性,不需要doublewrite技术。
3.1.1.redo log file结构
一个数据库实例可能有多个redo log file,结构如下图所示:
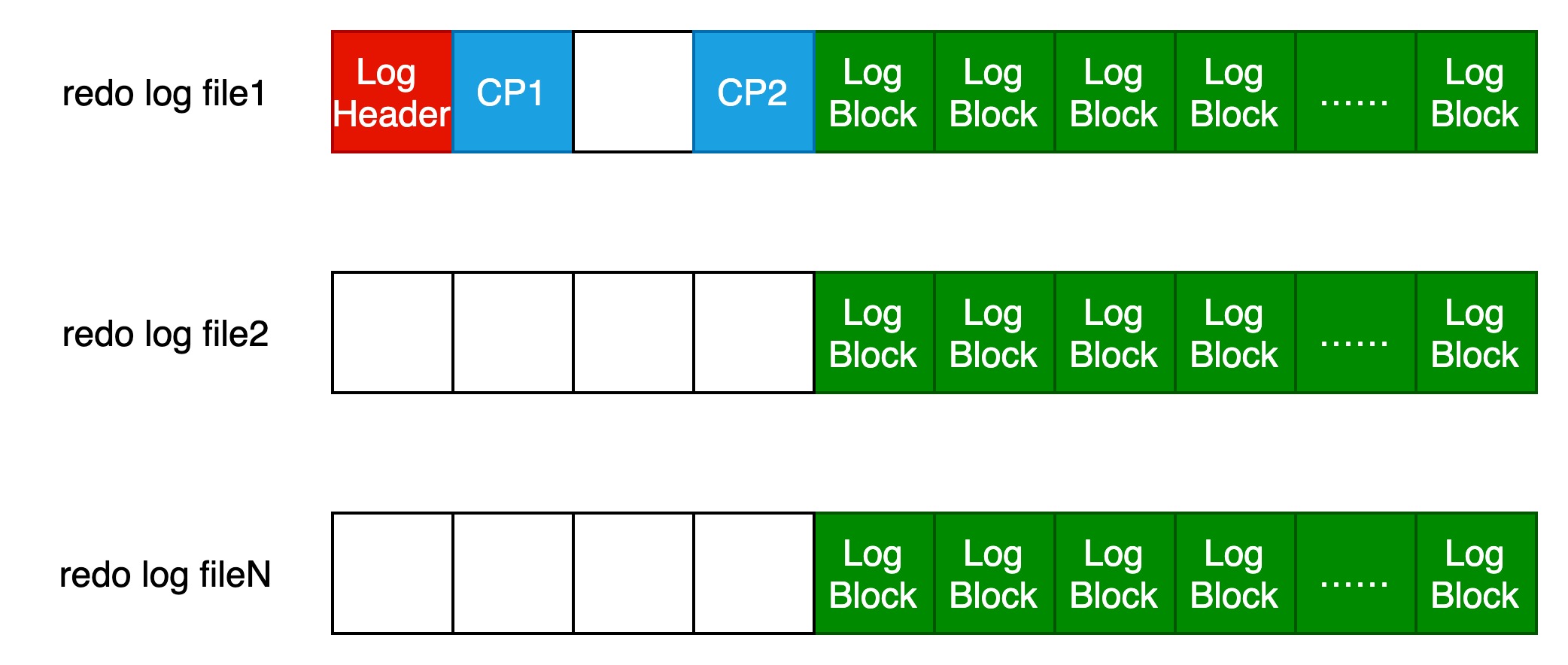
第一个redo log file中保存的是最新的重做日志,前2KB的数据保存的是Log Header、2个Checkpoint、一个空块,每个块都是512字节。后面的数据都是Log Block。
2个Checkpoint(CP1和CP2)的设计是交替写入,这样的设计避免因介质失败而导致无法找到可用的checkpoint的情况。
其他的redo log file中前2KB数据都是空的block,之后的保存的都是Log Block。
3.1.2.redo log日志条目格式
不同的数据库操作类型有不同的日志格式。但是都有同样的头部格式。如下图所示:

redo log type表示重做日志的类型,目前有几十种redo log记录类型,上图中列出两种insert和delete。
space表示表空间的id,指定记录属于哪张表。
page_no表示页的偏移量。
Innodb存储引擎的存储是基于页的,所以redo log日志也是基于页的。
3.2.redo log如何实现原子性
redo log写入机制控制原子性。
3.3.redo log如何实现持久性
redo log由两部分组成
(1)内存中的redo log buffer,易丢失
(2)重做日志文件redo log file,是持久化的。
Innodb通过Force Log at Commit机制实现事务的持久性,即当事务提交(commit)时,必须先将该事务的所有日志写入到重做日志文件进行持久化。这里的重做日志包括redo log和undo log。
3.3.1.redo log buffer如何写入redo log file
redo log buffer根据一定规则将内存中的log block刷新到磁盘,这些规则有:
(1)事务提交时进行flush
(2)当log buffer中有一半的内存空间已经被使用,需要flush到磁盘。
(3)log checkpoint时需要flush到磁盘。
3.4.redo log的恢复
redo log记录的是物理日志恢复的速度比逻辑日志(比如二进制日志)要快。
Innodb自身对恢复进行了一定程度的优化,如顺序读、并行应用redo log等,这样可以进一步提高数据库恢复的速度。
由于checkpoint表示已经刷新到磁盘页上的LSN,因此在恢复过程中仅需恢复checkpoint开始的日志部分。
LSN是Log Sequence Number的缩写,表示日志序列号,占用8字节,单调递增。LSN还可以表示redo log写入的总量,表示checkpoint的位置,还表示页的版本号。
4.undo log
undo log是存放在数据库内部的一个特殊段(segment)中,称为undo段。undo段位于共享表空间内。
undo log不是物理日志,而是逻辑日志,因此只是将数据库逻辑地恢复到原来的样子。
4.1.根据undo log回滚的过程
undo log用来帮助事务回滚和MVCC的功能。
假如往一个表中插入10万数据,表空间会增大。当用户执行rollback时,会将插入的事务进行回滚,但是表空间的大小并不会因为回滚而减少。
当Innodb执行回滚时,实际上做的是与事务相反的操作。
(1)对于每一个insert操作,回滚会执行一个delete操作。
(2)对于每一个delete操作,回滚会执行一个insert操作。
(3)对于每一个update操作,回滚会执行一个相反的update操作。
undo log产生会伴随redo log的产生,因为undo log也需要持久性保护。
4.2.undo log实现MVCC
Innodb中,MVCC通过undo log来实现。当用户读取一行数据时,若该数据被其他事务加锁占用,当前事务可以通过undo读取之前的行版本信息,以此实现非锁定读。
4.3.undo log如何实现一致性
undo log通过回滚操作和MVCC实现一致性。