Ray简介
Ray官方说明为:Ray is at the center of the world's most powerful AI platforms. It precisely orchestrates infrastructure for any distributed workload on any accelerator at any scale.
核心概念
Ray有以下核心概念
(1)Ray Application
一个包含Ray代码的程序,并且代码调用ray.init()方式,其实是对一组Ray Tasks或者Actors的封装
(2)Dependencies或者Environment
Application需要运行的Ray代码之外的任何内容,包括文件、包和环境变量。
(3)Files
运行Application需要的任务代码文件、数据文件或者其他文件
(4)Packages
Ray Application运行时需要的额外的包,通常可以通过pip或者conda安装
(5)Local machine和Cluster
提交Job的机器叫Local machine,运行Ray job的叫Ray Cluster。
(6)Job
一个Job是一个单独的Application,通常是来自同一代码的Ray Tasks、Objects和Actors的集合
特点
适用场景
Ray服务架构
Ray Cluster
参考官网,Ray Cluster服务架构如下图所示:
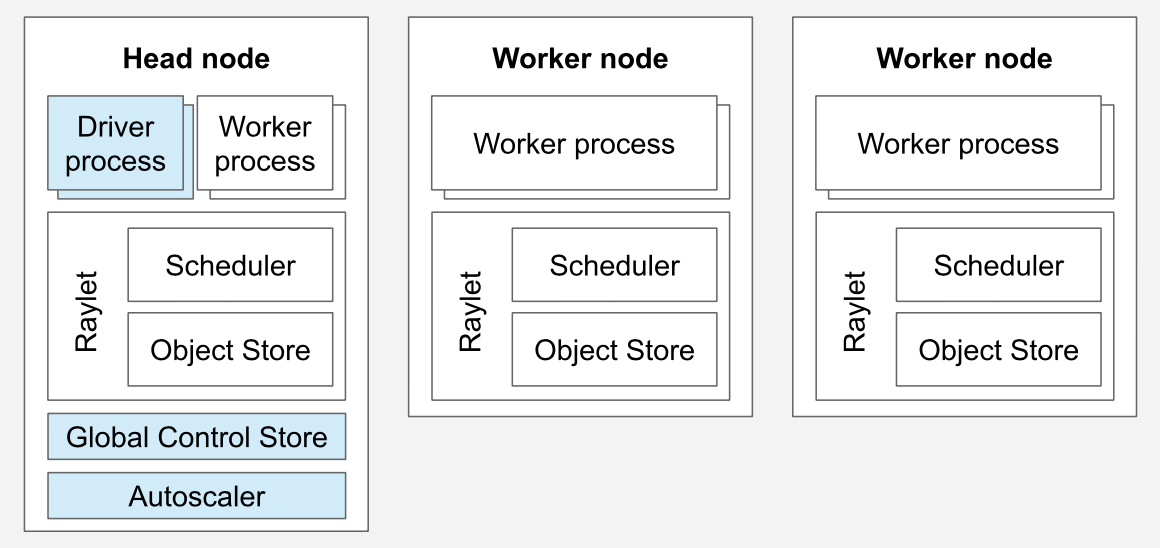
一个Ray Cluster包含一个Head Node和多个与之连接的Worker Nodes
Head Node
每一个Ray Cluster都有一个Head Node,Head Node上运行着管理集群的单进程实例,比如Autoscaler和Global Control Store(GCS),还运行着多个Driver进程,负责运行Ray Job。同时,也跟其他Worker Node一样,可以负责执行Ray Task和Actor。但是也可以通过配置,然后Head Node执行Task和Actor的CPU资源为0,Head Node就会不再执行Worker Node的任务了。
Driver Process
负责发起和控制Ray Job(任务)的主进程。一个典型的 Ray 应用由用户编写的 Python 脚本运行,脚本会通过 Driver Process 提交任务到 Ray 集群中。
主要职责包括:
(1)任务提交:Driver 负责提交 Ray 任务和 actor 到 Ray 集群。Driver 将任务发送到 Ray 的调度系统,Ray 再根据当前的集群状态将任务调度到合适的节点执行。
(2)与 Ray API 交互:用户通过 Ray 的 API 提交任务或创建 actor,Ray 的 Driver Process 就会与 Ray 集群的核心服务(如 GCS、Scheduler)通信,负责解释用户的操作并将其转化为集群操作。
(3)管理作业生命周期:Driver 负责管理整个任务或作业的生命周期,追踪任务的完成、失败或重试等情况。
每个运行 Ray 应用的用户程序都会对应一个 Driver Process,它是用户与 Ray 集群交互的接口。
Global Control Store(GCS)
GCS 是 Ray 的全局控制存储,它作为系统中的一个中心化服务,负责管理和存储集群的全局元数据。在 Ray 集群的 head node 上运行。主要职责包括:
(1)Actor 管理:GCS 负责管理集群中所有 actor 的元数据,例如 actor 的位置、状态、资源使用情况等。GCS 通过存储这些元数据,使得 Ray 能够追踪和调度不同节点上的 actor。
(2)任务调度信息存储:GCS 也存储关于任务队列、调度策略、任务状态等信息。GCS 可以被任务调度器用来根据全局状态来做出最优的调度决策。
(3)资源管理:Ray 集群中的资源(CPU、GPU 等)由 GCS 管理。它通过追踪各个节点的资源使用情况,确保任务能够被合理地调度到有足够资源的节点上。
GCS 是 Ray 集群中的一个关键组件,允许不同的节点共享信息、同步状态。
Autoscaler
Ray的自动伸缩器(Autoscaler)是一个运行在Head Node的进程,当Ray的工作负载对资源的需求(CPU、Memory)超过了当前集群的容量时,自动伸缩器就会尝试增加Worker Node。如果一个集群的工作负载很小,有闲置的Worker Node,自动伸缩器也会把闲置的Worker Node从集群中移除。
需要注意的是:
(1)Autoscaler只记录Ray的task和actor的资源使用情况,并且根据Task和Actor对资源的显示需求做出响应。应用级的监控指标和物理机的资源占用情况,不影响Autoscaler的工作。
(2)如果请求启动Task或者Actor,发现集群资源不够,Autoscaler会将请求排队,然后扩容集群节点数,以满足Task和Actor的运行需求。
(3)自动伸缩器可以通过扩容降低集群负载,也可以通过缩容提高资源利用率,但是扩容节点会增加开销,并且影响集群的稳定性,而且配置也比较复杂,所以很多情况下尽量不配置使用。
Worker Node
Worker Node不用运行Head Node的管理集群的进程,只能用来在Task和Actor上运行用户的代码。会参与Task和Actor基于资源的分布式调度,同时也会在集群内存中存储和分发Ray Objects。
应用架构
参考官网的应用架构
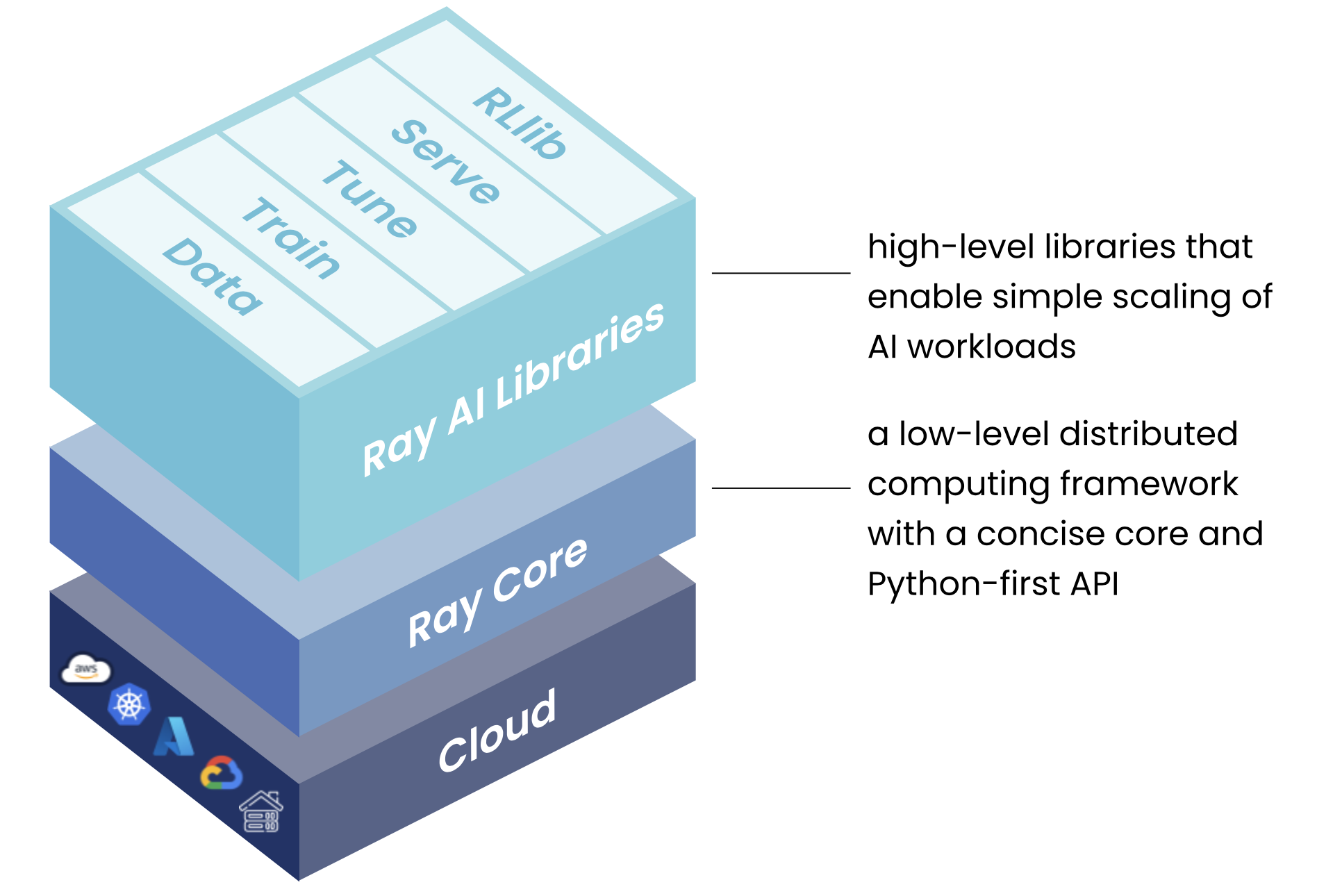
应用架构分为三层
Ray AI Libraries
一组开源、Python、特定领域的库,为机器学习工程师、数据科学家和研究人员提供可扩展和统一的机器学习应用工具包。
Data: 可扩展的、与框架无关的数据加载和转换,涵盖训练、调优和预测。
Train: 分布式多节点和多核模型训练,具有容错性,与流行的训练库集成。
Tune: 可扩展的超参数调整,以优化模型性能。
Serve: 可扩展和可编程的服务,用于部署用于在线推理的模型,并可选择微批处理来提高性能。
RLlib: 可扩展的分布式强化学习工作负载。
对于数据科学家来说,这些库可用于扩展单个工作负载,以及end-to-end的机器学习应用程序。对于机器学习工程师来说,这些库提供了可扩展的平台抽象,可用于轻松整合和集成来自更广泛的机器学习生态系统的工具。
Ray Core
一个开源、Python、通用、分布式计算库,使机器学习工程师和Python开发人员能够扩展Python应用程序并加速机器学习工作负载。
对于自定义的Application(应用),Ray Core的库可以使Python开发人员能够轻松构建可扩展的分布式系统,这些系统可以在笔记本电脑、集群、云或Kubernetes上运行。这是构建Ray AI库和第三方集成(Ray生态系统)的基础。
Ray Clusters
一组连接到Ray Head 节点的Worker节点。Ray Cluster可以是固定大小的,也可以根据群集上运行的Application请求的资源进行集群自动缩放。