Hudi架构
Hudi是一个事务性数据湖平台,它将数据库和数据仓库功能引入数据湖。
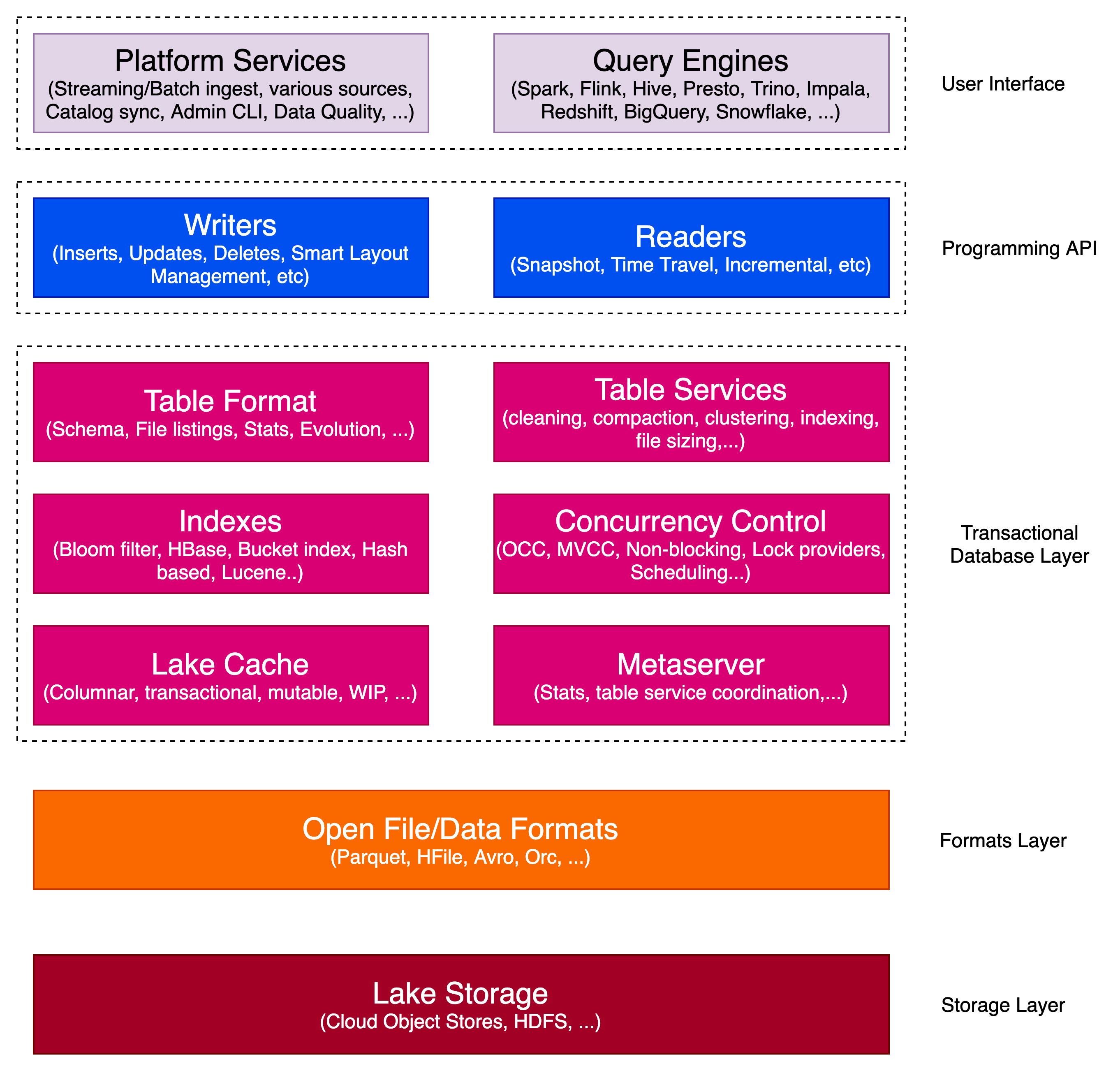
Hudi 的核心定义了一种表格式,用于组织存储系统内的数据和元数据文件,从而实现 ACID 事务、高效索引和增量处理等功能。
write
写入流程
hudi写的整体流程如下图所示:
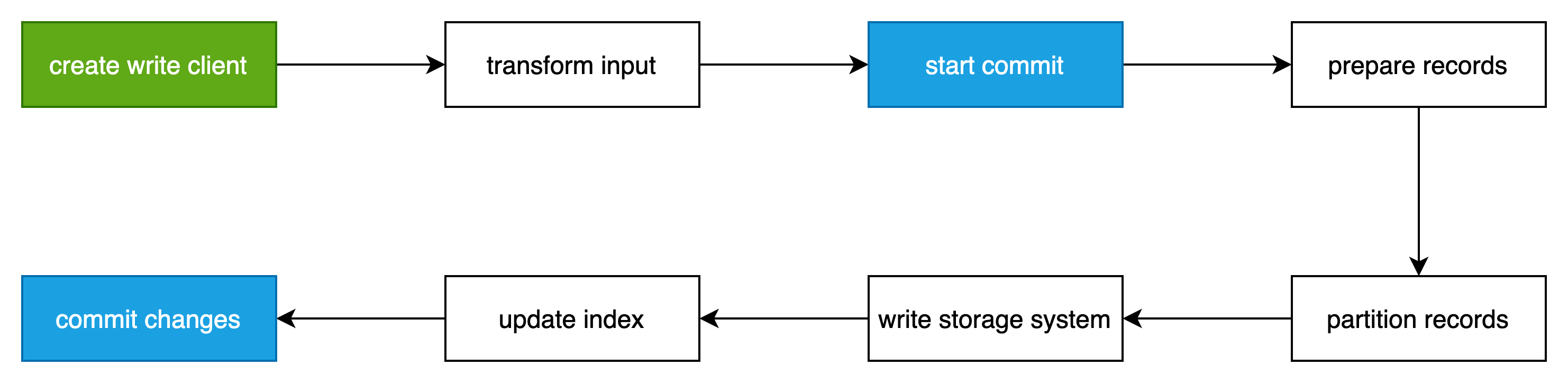
分为以下8个步骤
create write client
Hudi写数据是通过创建引擎兼容的写客户端实例来实现的。Spark 使用 SparkRDDWriteClient ,Flink 使用 HoodieFlinkWriteClient ,Kafka Connect 使用 HoodieJavaWriteClient 。
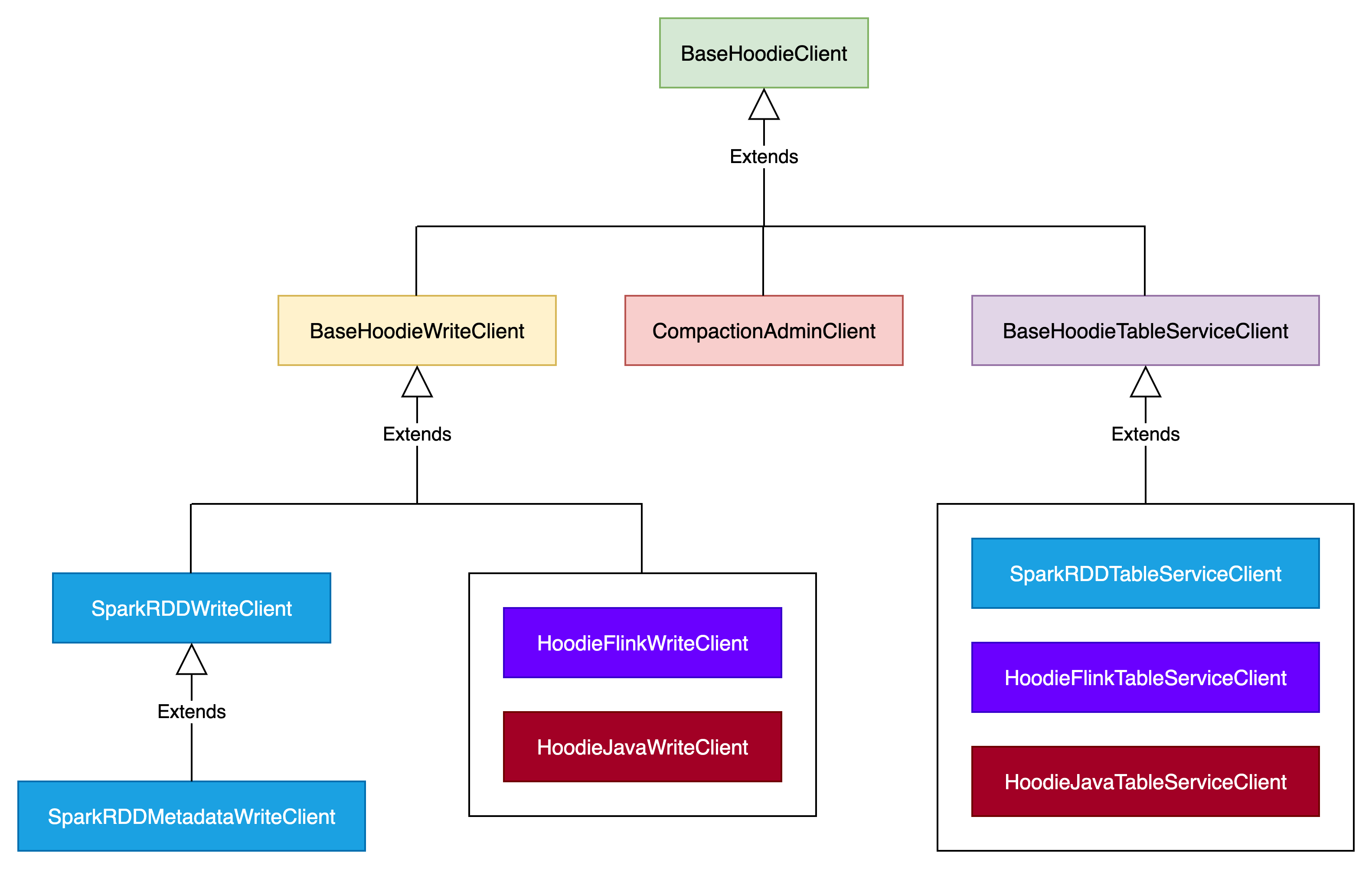
构建write client实例相关的配置在Hudi表属性中。
transform input
在写入客户端处理输入数据之前,会发生多个转换,包括 HoodieRecord 的构造和架构协调。
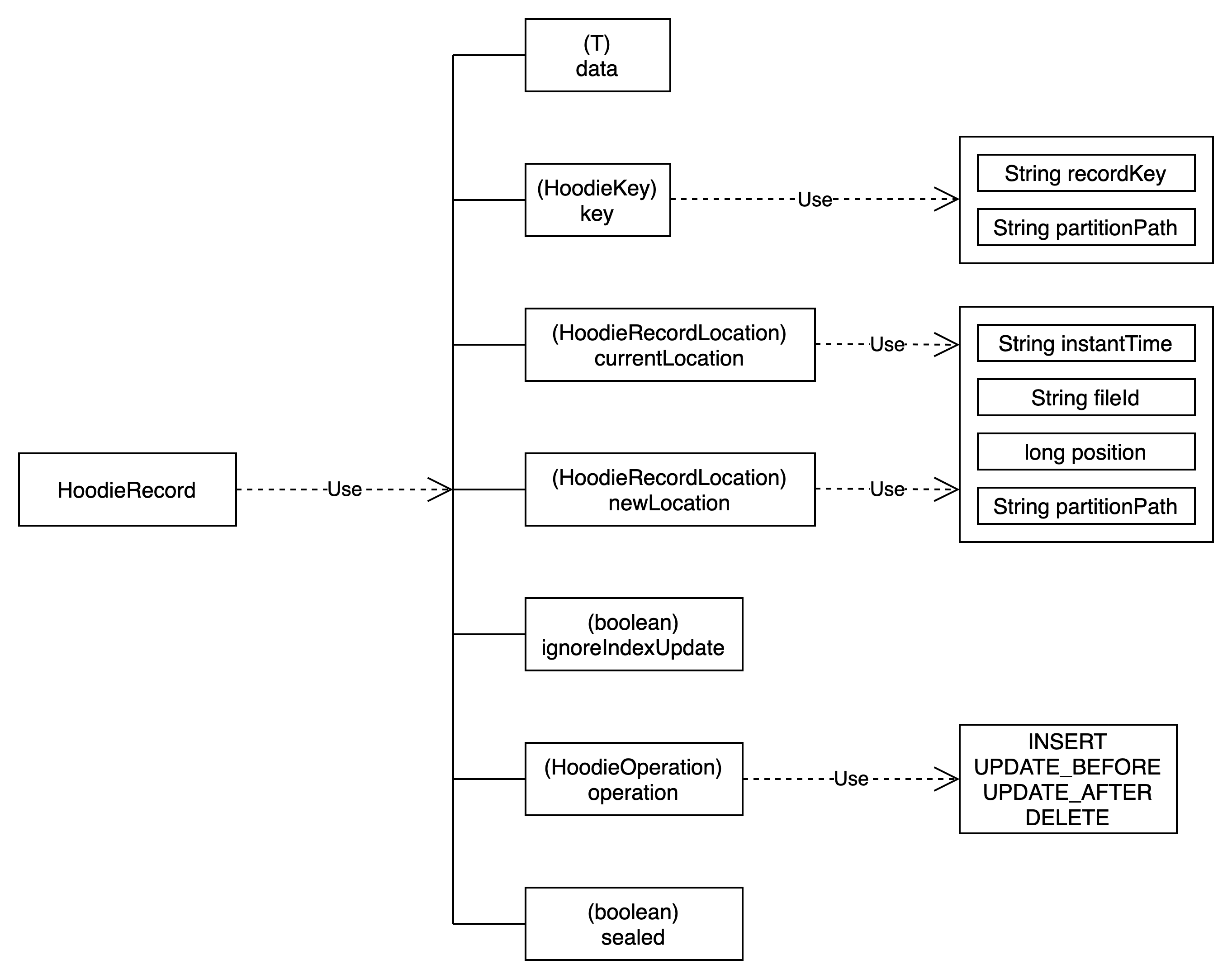
Hudi使用 HoodieKey 模型来标识唯一记录,该模型由“recordKey”和“partitionPath”组成。这些值是通过实现 KeyGenerator API 来填充的。该 API 可以灵活地根据输入模式提取自定义字段并将其转换为键。
“currentLocation”和“newLocation”均由 Hudi 时间线的操作时间戳和文件组的 ID 组成。时间戳指向特定 FileGroup 内的 FileSlice。“位置”属性用于使用逻辑信息来定位物理文件。如果“currentLocation”不为空,则表示表中存在具有相同键的记录,而“newLocation”则指定应将传入记录写入何处。
“data”字段是一个通用类型,包含记录的实际字节,也称为有效负载。通常,此属性实现 HoodieRecordPayload ,它指导引擎如何将旧记录与新记录合并。从 0.13.0 版本开始,引入了新的实验接口 HoodieRecordMerger 来替代 HoodieRecordPayload 并作为统一的合并 API。
start commit
写入客户端始终检查表的时间轴上是否还存在任何失败的操作,并通过在时间轴上创建“请求的”提交操作来启动写入操作之前相应地执行回滚。
prepare records
所提供的 HoodieRecord 可以根据用户配置和操作类型选择性地进行重复数据删除和索引。如果需要重复数据删除,具有相同键的记录将被合并为一条。如果需要索引,如果记录存在,则将填充“currentLocation”。
partition records
这是一个重要的预写入步骤,它确定哪个记录进入哪个文件组,并最终进入哪个物理文件。传入的记录将被分配到更新桶和插入桶,这意味着后续文件写入的策略不同。每个桶代表一个 RDD 分区,用于分布式处理,就像 Spark 的情况一样。
write storage system
这是实际 I/O 操作发生的时间。使用文件写入句柄创建或附加物理数据文件。在此之前,还可以在 .hoodie/.temp/ 目录中创建标记文件,以指示将对相应数据文件执行的写入操作类型。这对于高效回滚和冲突解决方案非常有价值。
update index
数据写入磁盘后,可能需要立即更新索引数据以保证读写的正确性。这特别适用于写入期间不同步更新的索引类型,例如托管在 HBase 服务器中的 HBase 索引。
commit changes
在最后一步中,写入客户端将承担多个任务以正确完成事务写入。例如,它可以运行预提交验证(如果已配置)、检查与并发编写器的冲突、将提交元数据保存到时间线、使 WriteStatus 与标记文件协调一致,等等。
UPSERT写操作
CoW 表的 Upsert 流程如下图所示:
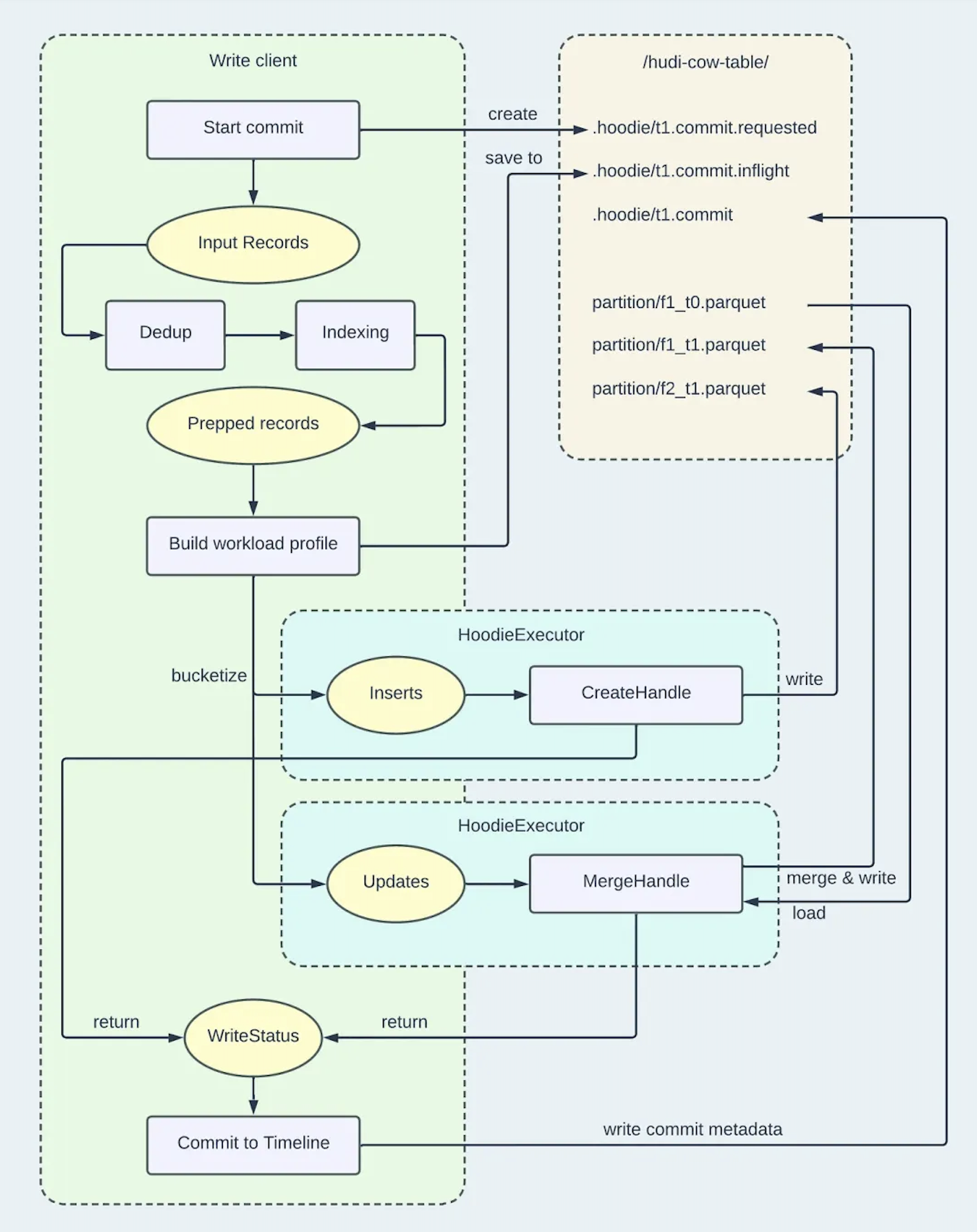
整个操作分为以下五个过程
(1)写入客户端开始提交并在时间轴上创建“requested”操作。
(2)输入记录经历准备步骤:合并重复项,并由索引填充目标文件位置。此时,我们已经有了要写入的确切记录,并知道表中存在哪些记录,以及它们各自的位置(文件组)。
(3)准备好的记录分为“更新”和“插入”存储桶。最初,构建 WorkloadProfile 是为了收集有关相关物理分区中的更新和插入数量的信息。然后,该数据被序列化为时间轴上的“飞行中”动作。随后,根据WorkloadProfile生成桶来保存记录。对于更新,每个更新文件组都被分配为一个更新存储桶。在插入的情况下,小文件处理逻辑开始发挥作用:任何小于指定阈值(由 hoodie.parquet.small.file.limit 确定)的 BaseFile 都会成为容纳插入的候选文件,其封闭的 FileGroup 被指定为更新存储桶。如果不存在这样的 BaseFile,则会分配插入存储桶,并稍后为其创建新的 FileGroup。
(4)然后通过文件写入句柄处理分桶记录,以实现实际的持久性存储。对于更新存储桶中的记录,使用“合并”句柄,从而在现有文件组内创建新的文件切片(通过与旧文件切片中的数据合并来实现)。对于插入存储桶中的记录,使用“创建”句柄,从而创建全新的文件组。此过程由 HoodieExecutor 完成,它采用生产者-消费者模式来读取和写入记录。
(5)写入所有数据后,文件写入句柄将返回 WriteStatus 集合,其中包含有关写入的元数据,包括错误数、执行的插入数、总写入大小(以字节为单位)等。该信息被发送回 Spark 驱动程序进行聚合。如果没有发生错误,写入客户端将生成提交元数据并将其作为已完成的操作保留在时间轴上。
MoR表的UPSERT也类似,使用一组不同的条件来确定用于更新和插入的文件写入句柄的类型。
INSERT和BUKL_INSERT写操作
插入流程与更新插入非常相似,主要区别在于缺少索引步骤。这意味着整个写入过程会更快(如果关闭重复数据删除会更快),但可能会导致表中出现重复。批量插入遵循与插入相同的语义,这意味着它也可能由于缺乏索引而导致重复。然而,区别在于批量插入缺乏小文件处理。记录分区策略通过设置 BulkInsertSortMode 确定,也可以通过实现 BulkInsertPartitioner 自定义。Bulk Insert 还默认为 Spark 启用行写入模式,绕过“转换输入”步骤中的 Avro 数据模型转换,并直接使用引擎原生数据模型 Row 。此模式提供更高效的写入。总体而言,批量插入通常比插入性能更高,但可能需要额外的配置调整来解决小文件问题。
INSERT OVERWRITE写操作
插入覆盖用提供的记录完全重写分区。此流程可以有效地视为删除分区和批量插入的组合:它从输入记录中提取受影响的分区路径,将这些分区中的所有现有文件组标记为已删除,并同时创建新的文件组来存储传入记录。
插入覆盖表是插入覆盖的变体。它不是从输入记录中提取受影响的分区路径,而是获取表的所有分区路径以进行覆盖。
DELETE写操作
删除流程可以视为更新插入流程的特例。主要区别在于,在“转换输入”步骤中,输入记录被转换为 HoodieKey 并传递到后续阶段,因为这些是识别要删除的记录所需的最少数据。需要注意的是,此过程会导致硬删除,这意味着目标记录将不会存在于相应文件组的新文件切片中。
DROP PARTITION写操作
与上面介绍的流程相比,删除分区遵循完全不同的流程。它采用物理分区路径列表,而不是输入记录,该列表是通过 hoodie.datasource.write.partitions.to.delete 配置的。由于没有输入记录,因此索引、分区和写入存储等过程不适用。删除分区将目标分区路径的所有文件组 ID 保存在时间轴上的 .replacecommit 操作中,确保后续写入者和读取者将它们视为已删除。